Categories

Blog posts about QNAP's products and technologies.
Avec la croissance rapide des applications d’IA et de HPC (High-Performance Computing), les volumes de données et la densité de calcul continuent d’augmenter. Qu’il s’agisse de l’entraînement de grands modèles de langage, de la simulation du changement climatique ou du traitement de séquences génétiques, ces charges de travail dépendent fortement d’un accès rapide et stable à données. Si les systèmes Stockage ne parviennent pas à suivre le rythme des GPU et des algorithmes, ils deviendront des goulets d’étranglement critiques pour la performance et la rentabilité.
De même, des scénarios tels que le montage vidéo 4K/8K, la VDI, les Virtualisation d’entreprise et les services cloud exigent également une plus grande stabilité et des capacités de traitement en temps réel de la part des systèmes Stockage. Pour relever ces défis, les architectures All-Flash et la technologie iSCSI + RDMA deviennent de plus en plus des choix courants. Cependant, pour exploiter pleinement leur potentiel, la clé réside dans l’optimisation continue de la couche logicielle du système Stockage.
QNAP s’est toujours concentré sur la maximisation du potentiel des ressources sous-jacentes dans le système d’exploitation QuTS hero. Le système a intégré plusieurs conceptions clés pour améliorer les performances et continue de l’améliorer à plusieurs niveaux afin de répondre aux exigences évolutives du calcul et de Stockage.
Cependant, l’amélioration des performances logicielles est un effort continu, d’autant plus que les avancées matérielles ouvrent constamment de nouvelles opportunités pour une optimisation plus poussée. Grâce à l’analyse du système, l’équipe QNAP a identifié deux axes clés au niveau système comme points d’entrée pour une optimisation continue :
1. Amélioration des performances pour le calcul multi-cœur et parallèle
Avec l’augmentation continue du nombre de cœurs de processeur, les systèmes débloquent de plus grandes capacités de traitement parallèle. En introduisant un modèle multithread dans davantage de modules de travail et des mécanismes de découplage des tâches, en analysant en continu les caractéristiques des charges de travail et les stratégies d’allocation des threads dans le flux de traitement, et en optimisant l’affinité des threads ainsi que les mécanismes de traitement parallèle, les performances multi-cœurs peuvent être pleinement exploitées dans les applications pratiques.
2. Amélioration continue de la mémoire etEfficacité du sous-système d’E/S
Bien que les performances des processeurs se soient rapidement améliorées, la conception des canaux d’E/S joue toujours un rôle crucial dans l’optimisation de l’efficacité d’E/S. En analysant en continu les goulets d’étranglement dans les chemins d’accès données et en mettant en œuvre les améliorations de conception nécessaires, les performances de transmission peuvent être encore renforcées, garantissant que l’ensemble du système fonctionne de manière cohérente pour atteindre une efficacité maximale.
En réponse aux goulets d’étranglement mentionnés ci-dessus, l’équipe QNAP a réalisé des optimisations approfondies sur les canaux données principaux. Nous adoptons une approche de conception intégrée depuis la pile réseau, en passant par la couche de transport iSCSI, jusqu’au système de fichiers backend (avec ZFS comme cœur), dans le but de rationaliser chaque étape du flux données et d’atteindre une transmission véritablement à haute vitesse.
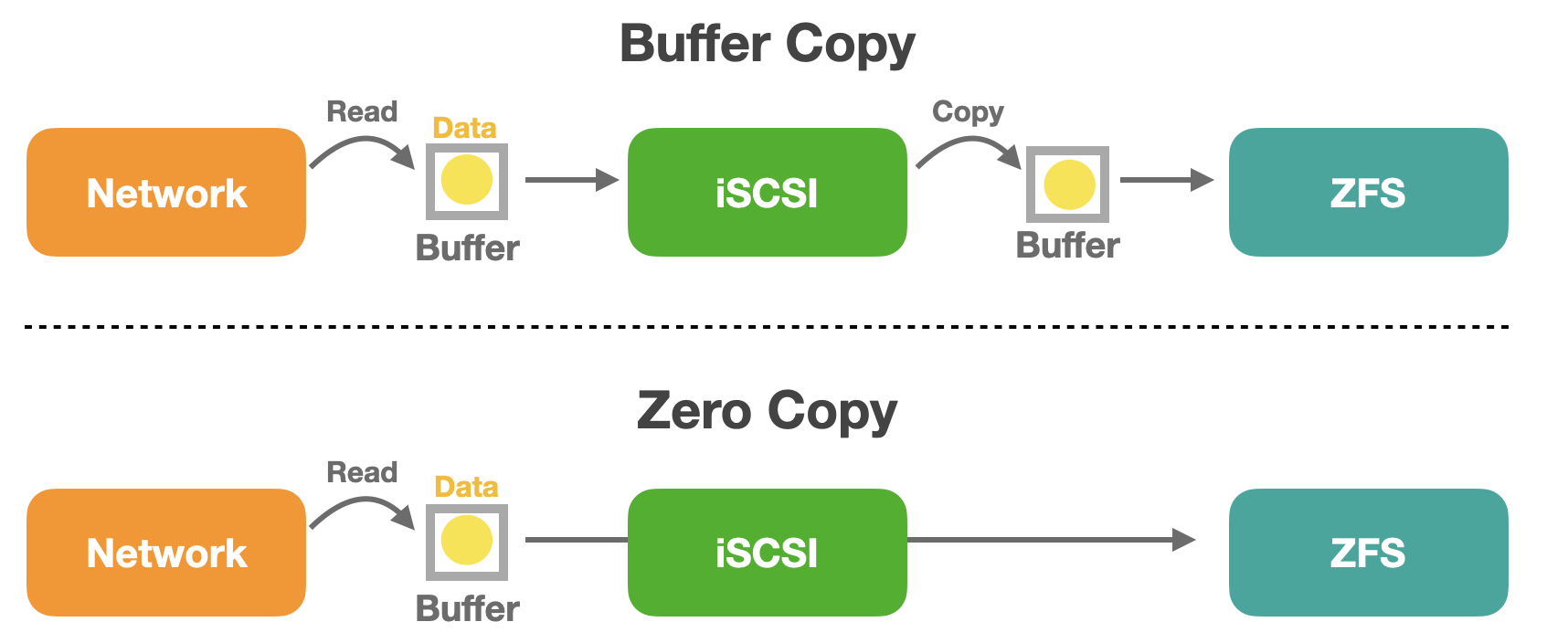
PrésentationZero-Copy: Réduire la migration de données et libérer les performances
Dans les architectures système modernes, l’intégration logicielle entre la couche de protocole de communication et la couche du système de fichiers est essentielle pour assurer un échange efficace de données et de Stockage. QuTS hero permet le transfert Zero-Copy de données depuis la pile réseau jusqu’à la couche iSCSI puis vers la couche du système de fichiers, évitant ainsi de multiples copies de données entre les modules principaux lors de la transmission. Cela réduit considérablement la charge du processeur et améliore l’efficacité du transfert de données.
Cela réduit non seulement la consommation de bande passante mémoire, mais aussi la latence, ce qui est particulièrement bénéfique pour les charges de travail I/O à haute fréquence telles que l’IA, le HPC et les plateformes Virtualisation. Un tel design intégré transforme l’iSCSI d’un protocole Stockage traditionnel en un composant essentiel d’un chemin données haute performance.
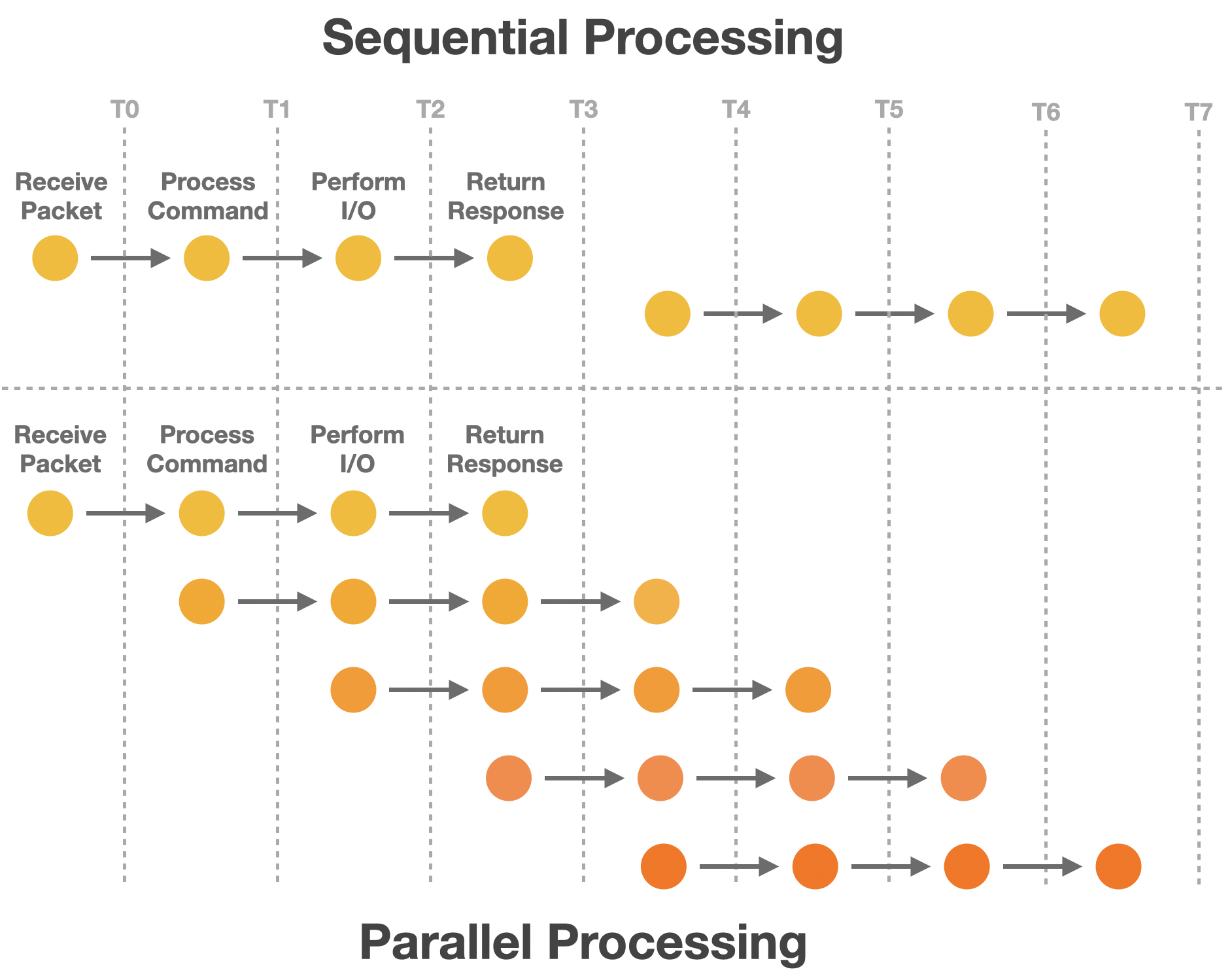
Découplage parallèle : Restructurer le flux de traitement iSCSI données
Traditionnellement, le module iSCSI gère la réception des paquets, l’analyse des commandes, la migration de données et la transmission des réponses de manière séquentielle. Lorsque les commandes et données sont traités de façon linéaire, cela peut facilement entraîner des goulets d’étranglement. Pour améliorer sa réactivité dans les applications réelles, l’architecture a été repensée avec un découplage des tâches et une parallélisation.
Nous séparons la planification du traitement de données et l’analyse des commandes pour les exécuter en parallèle, réduisant ainsi le blocage mutuel entre les étapes de traitement. Parallèlement, l’introduction du concept de Lock Splitting Aide permet d’éviter la contention des ressources causée par les verrous globaux, réduisant encore la surcharge de synchronisation et les coûts de migration de données lors du traitement parallèle, permettant ainsi des services iSCSI haute performance.
Planification collaborative inter-couches : Intégration des performances iSCSI et ZFS
Dans les systèmes Stockage modernes, la synergie des performances entre le module de transport iSCSI et le système de fichiers ZFS est essentielle pour la performance globale des I/O. Grâce à des stratégies coordonnées de planification des threads, les deux peuvent fonctionner indépendamment sans interférence dans des scénarios de forte concurrence, améliorant ainsi l’efficacité d’utilisation des ressources multi-cœurs et la fluidité du traitement données.
Après optimisation, nous avons observé des améliorations significatives des performances dans de multiples scénarios de test simulés, en particulier sous des charges I/O aléatoires, avec des améliorations notables de la réactivité globale du système et de l’efficacité du traitement. Dans certains cas de test, nous avons même observé jusqu’à environ 50 % d’amélioration des performances, démontrant l’efficacité claire des optimisations système dans des scénarios d’application spécifiques.
Ces résultats confirment que les optimisations coordonnées de QNAP dans des modules clés tels que iSCSI, ZFS et la logique de planification permettent de libérer efficacement le potentiel du système pour le traitement multi-cœurs et les architectures Stockage haute performance. Cela améliore l’efficacité globale de la transmission données et des chemins Stockage, offrant une base technique stable et fiable ainsi que des performances pour l’informatique à haute densité et les applications Virtualisation. Cela démontre également l’engagement technique de QNAP à optimiser continuellement l’expérience produit et à améliorer sa capacité à prendre en charge les applications critiques.
À l’avenir, nous continuerons d’investir dans les améliorations architecturales et les optimisations de performance afin de fournir une plateforme Stockage stable, prévisible et évolutive pour divers scénarios d’utilisation, de différentes tailles et types de charge.