Categories
Blog posts about QNAP's products and technologies.
前編ではZFSの基本的な構造について確認してみました。確認してみた中で、個人的にさらに疑問を感じた部分を掘り下げてみたいと思います。さらにその掘り下げの中で追加で感じた疑問についてもフォローしていきます。
従来のRAIDとZFSの決定的な違いは、データの場所を特定するための「計算式」を持っているかどうかです。ZFSの内部構造を紐解くと、その驚くべき柔軟性と堅牢性の正体が見えてきます。
※今回の話はQNAP QuTS heroの実装とは関係ありません。単純な技術的な深堀がメインです。
※深堀に際してAIに協力してもらっていますが、私の視点からも「挙動や設計思想からみても正しかろう」と判断した内容を載せているつもりです。
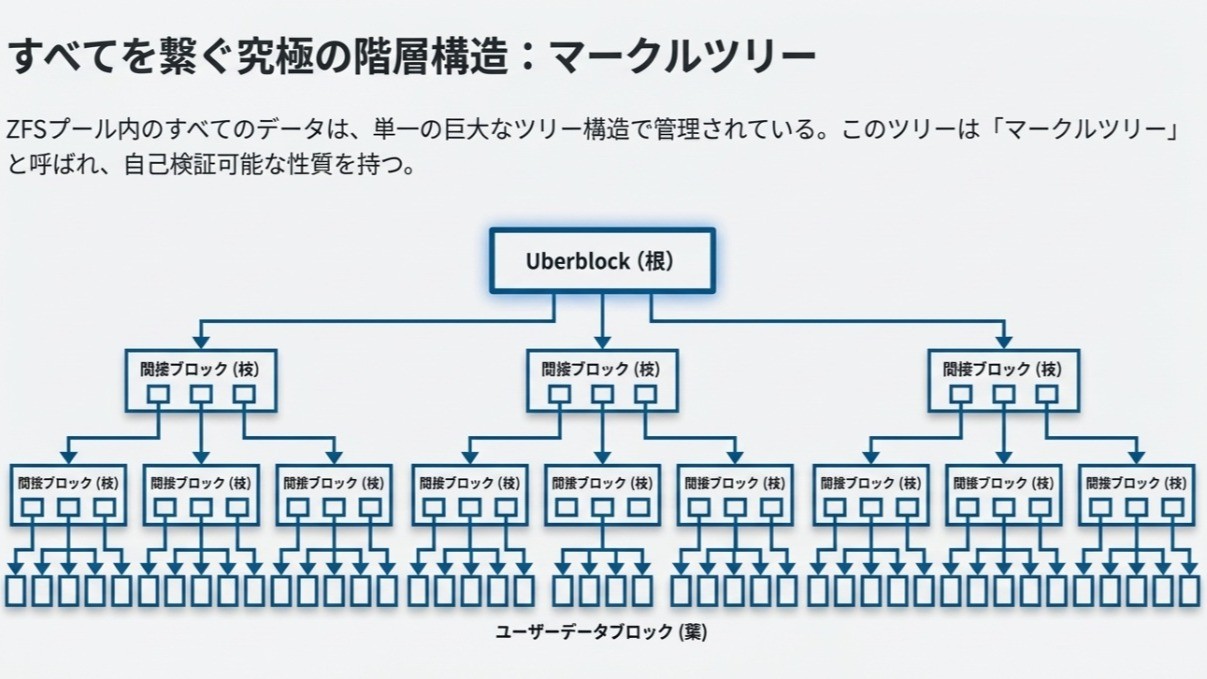
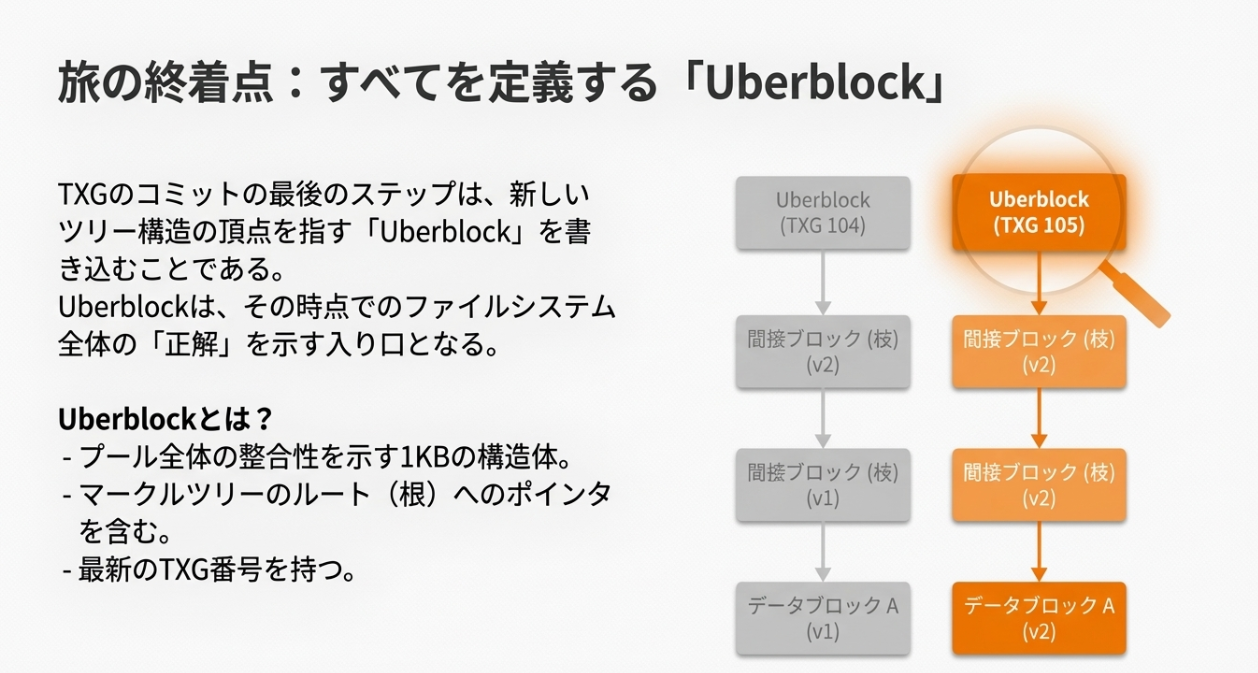
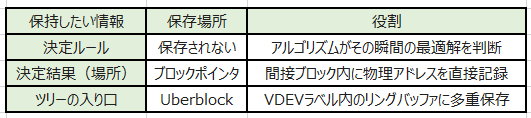
ZFSは、プール内の全データを巨大なツリー構造で管理しています。
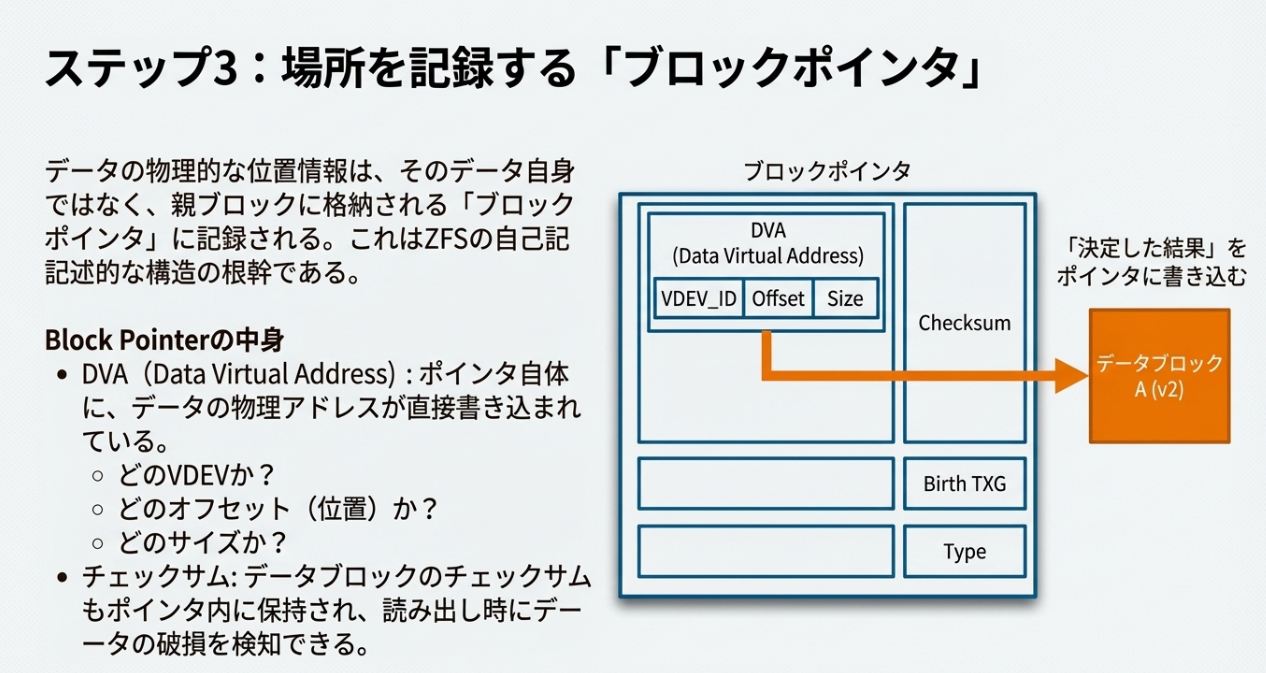
ここで重要なのが「ブロックポインタ(Block Pointer)」の役割です。ポインタ自体に「どのVDEVの、どのオフセットに、どのサイズで書いたか(DVA: Data Virtual Address)」が直接記録されています。
「書き込んだ結果(場所)」を親ブロックへ次々に書き込んでいく自己記述的な構造こそが、ZFSの柔軟性の源泉です。
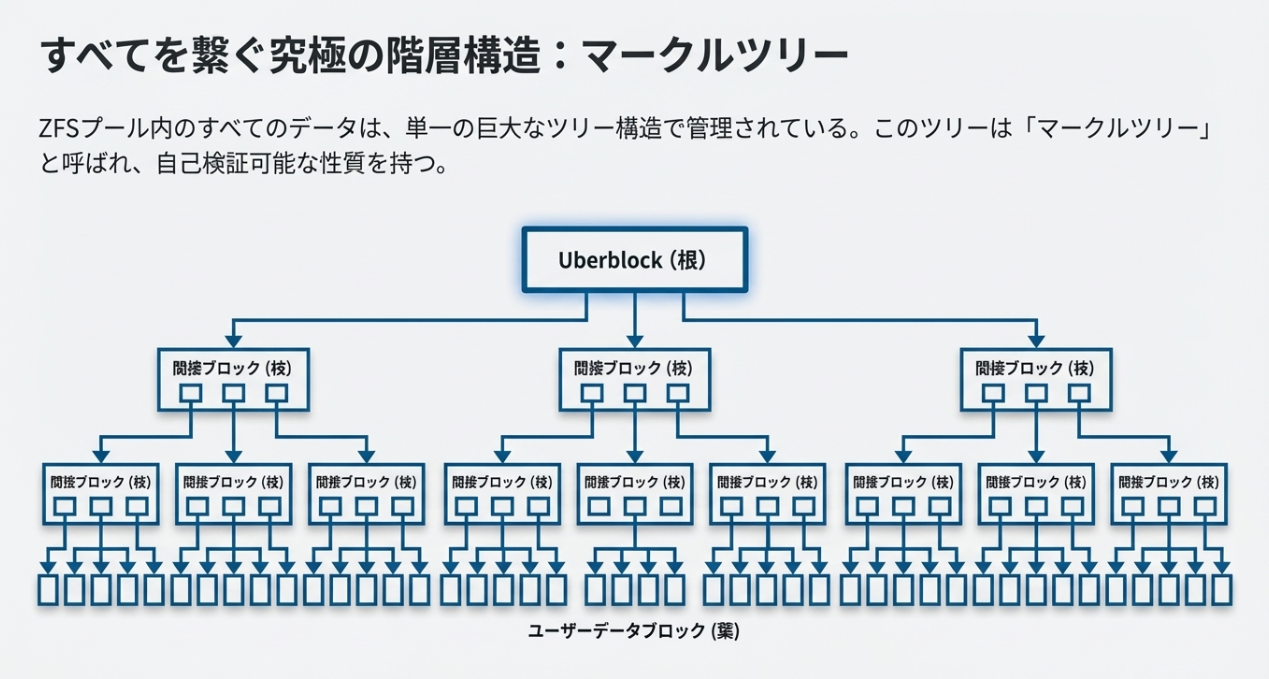
※これが動的ストライピングでデータを管理するための手法ですね。じゃぁこのUberblockが単一障害点となりえるのか?という点です。
プール全体の整合性を司るUberblock(1KB)は、SPOFを排除するために徹底的に多重化されています。
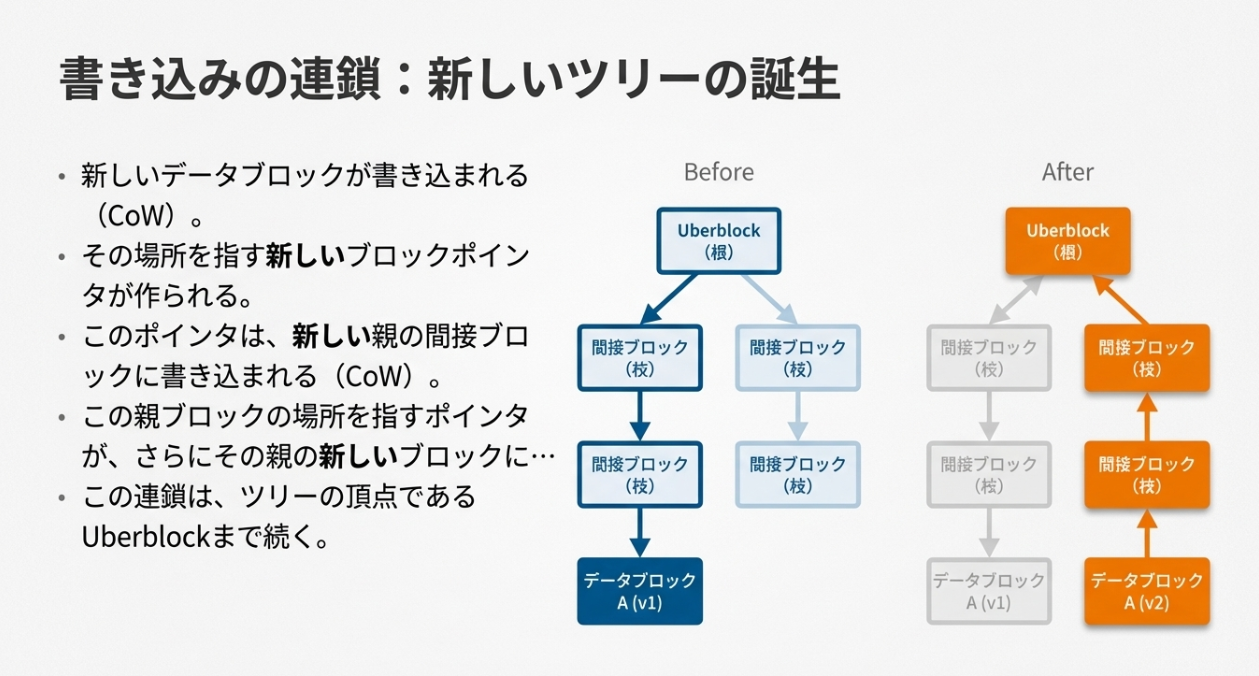
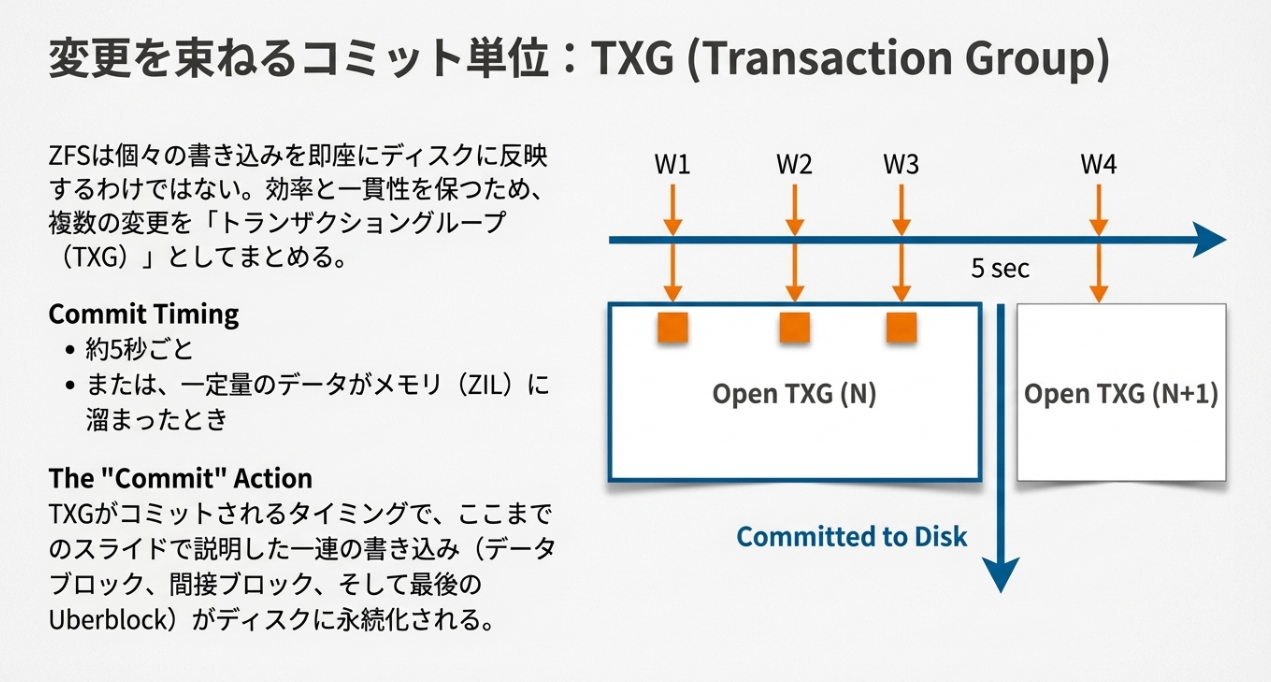
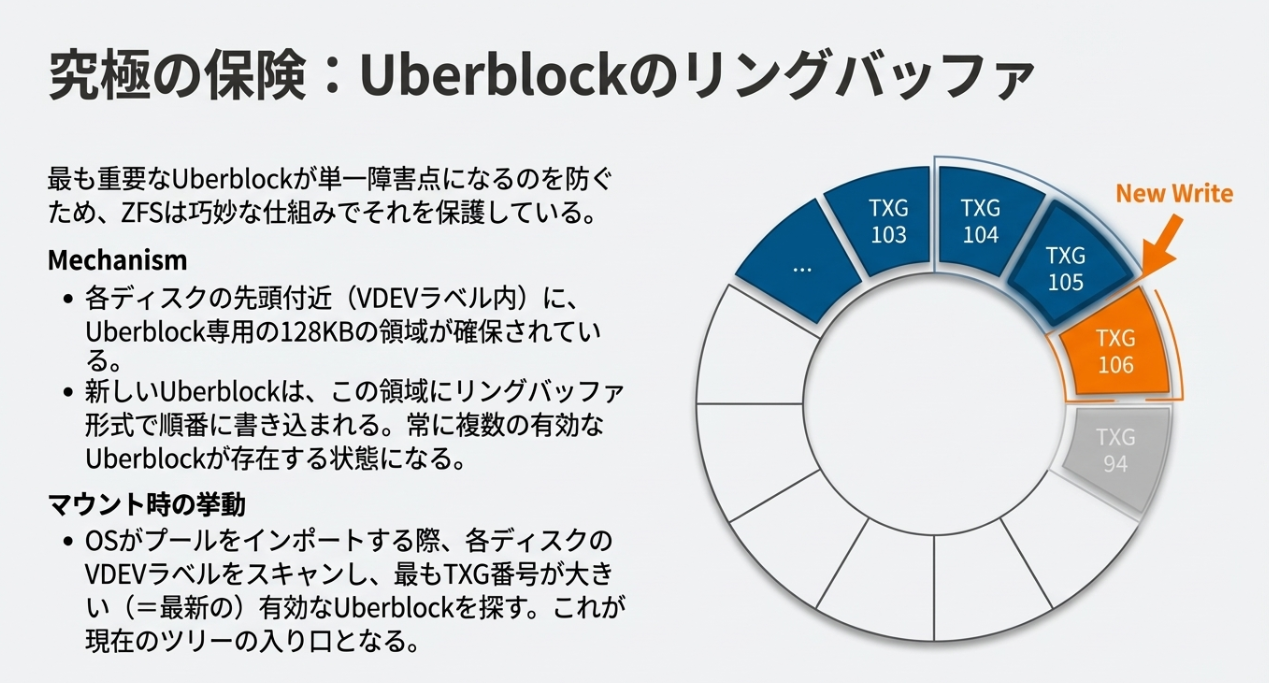
※TXGは、RAIDの中のeventカウントみたいなものですね。RAIDでは、単純にどのデバイスに記述されているSBが最新のものか?の判断くらいにしか使われていないですが、順番に更新することで、共倒れ(SBの一家全滅)を防いでいるイメージです。
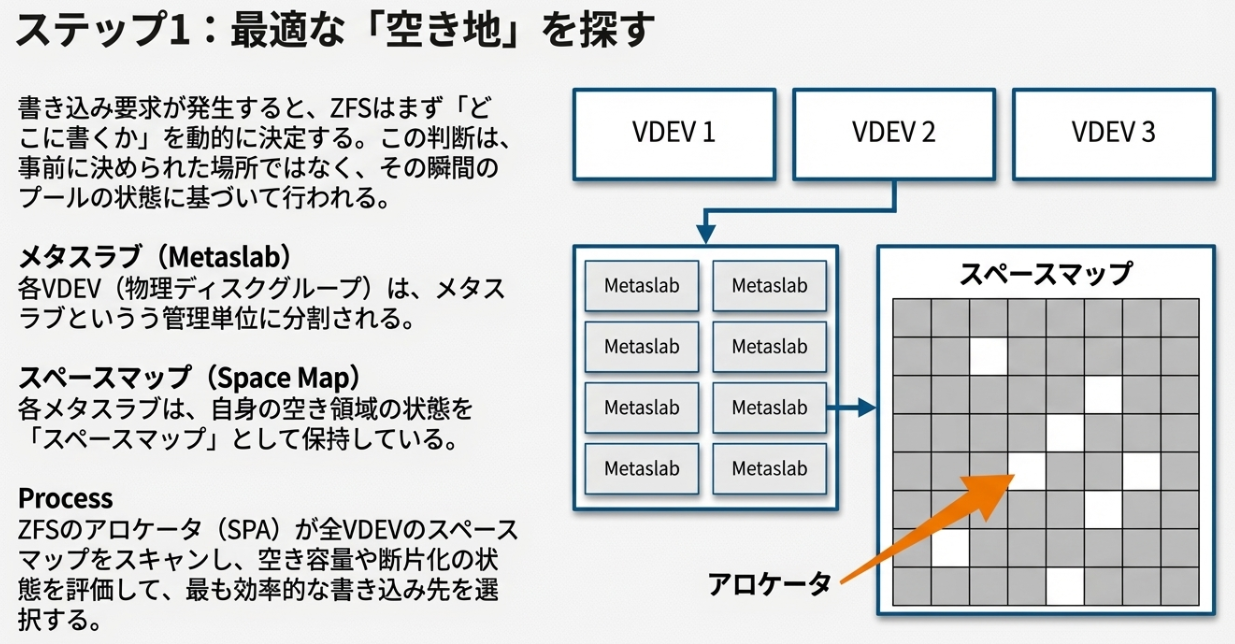
ZFSが「どこに書くか」をその都度判断できるのは、ディスク内部を細かくユニット化し、その空き状況をリアルタイムに把握しているからです。
ZFSは1つのVDEV(物理ディスク等)を、「メタスラブ」と呼ばれる数百〜数千の領域(通常、ディスク容量の約1%強)に分割して管理します。
各メタスラブの空き状況は、「スペースマップ」に記録されています。ここがZFSのユニークな点ですが、空き領域を単純な図解(ビットマップ)ではなく、「書き込みと解放の履歴(ログ)」として保持しています。
書き込みが発生すると、ZFSのアロケータは以下のステップで「最適解」を導き出します。
この一連のプロセスは「Unified Allocation Throttle」などの高度なアルゴリズムによって制御されており、「ルールを固定しない」からこそ、ディスクが満杯に近い状態でもパフォーマンスの低下を最小限に食い止めることができるようです。
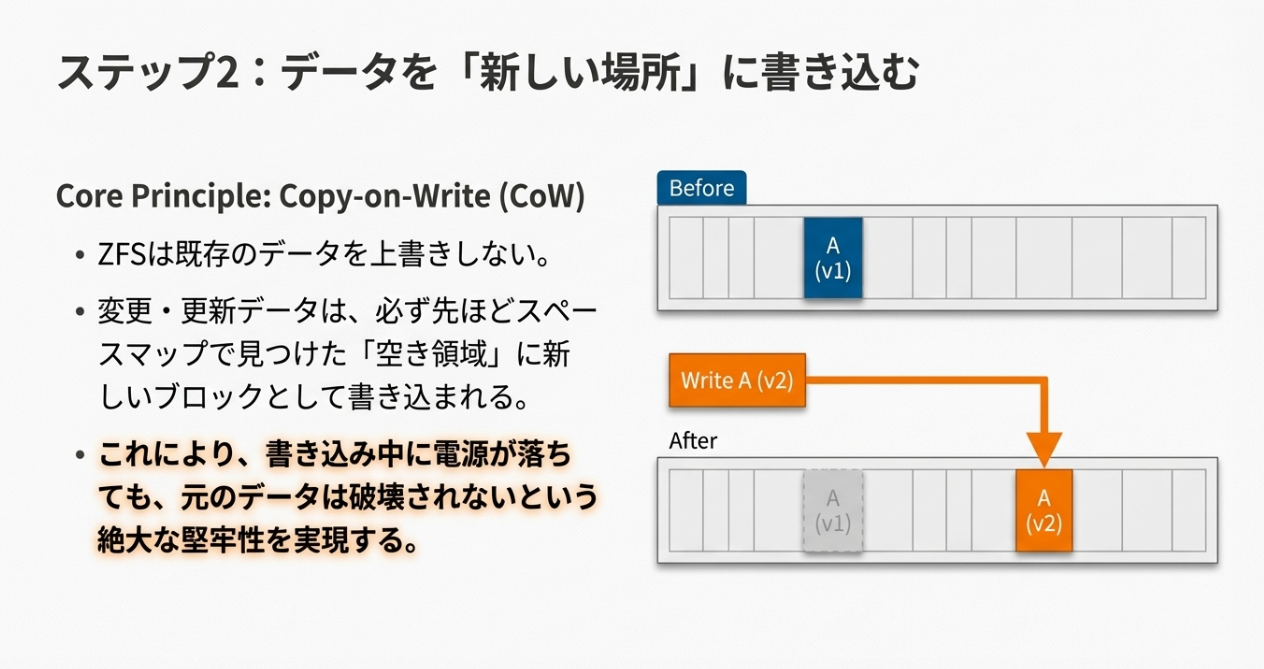
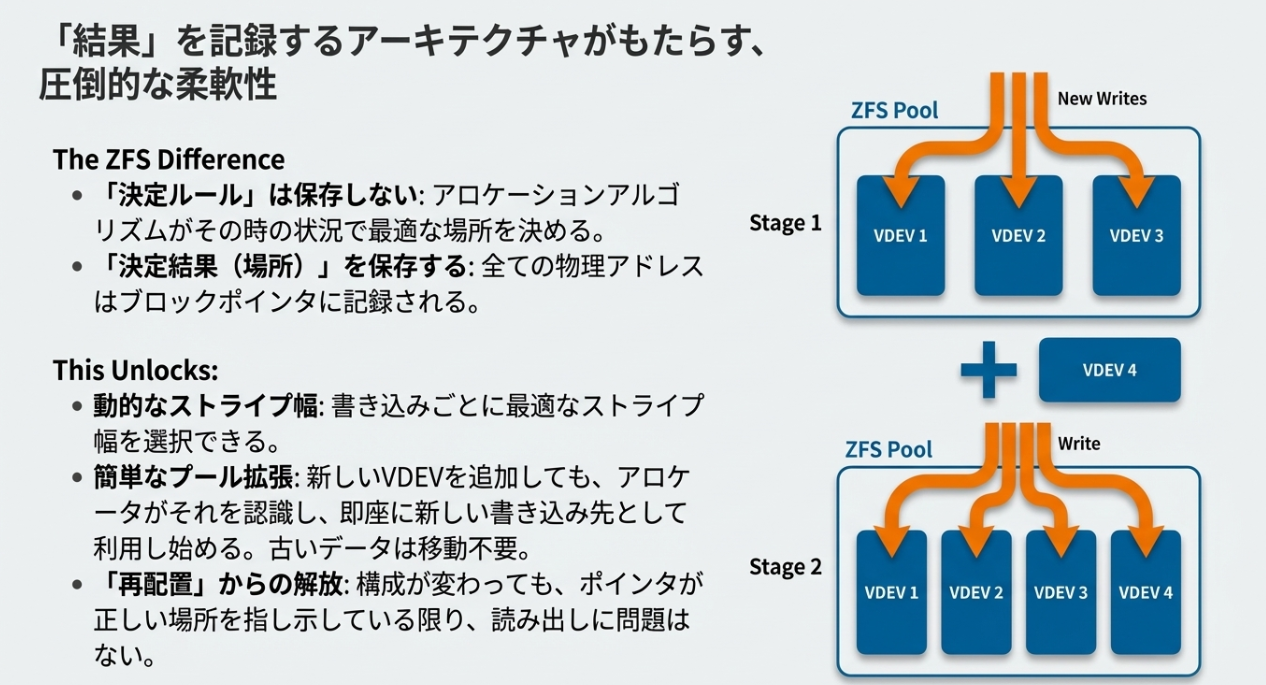
従来のRAIDは「データ位置 = LBA / ディスク数」といった固定の計算式に依存していたため、構成変更には大規模なデータの再配置が必要でした。
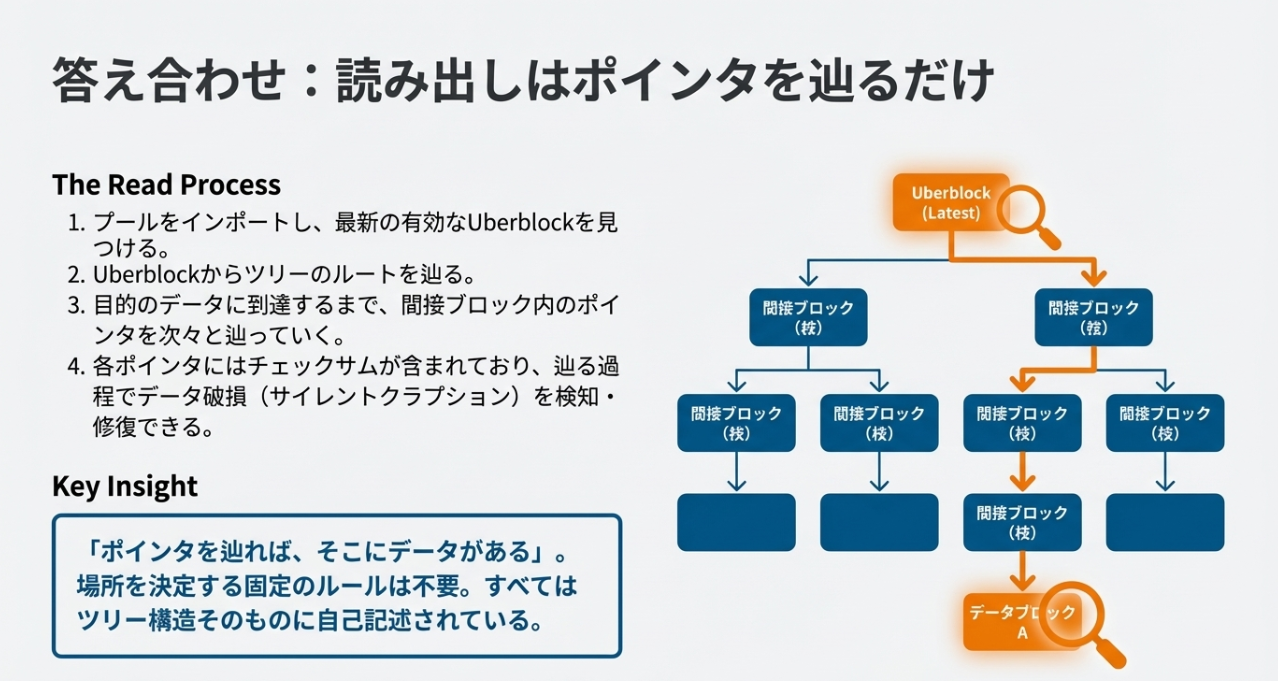
ZFSは「ポインタさえ辿ればデータがある」構造のため、ストライプ幅が変わろうが、新しいディスクが増えようが、読み出しには影響しません。
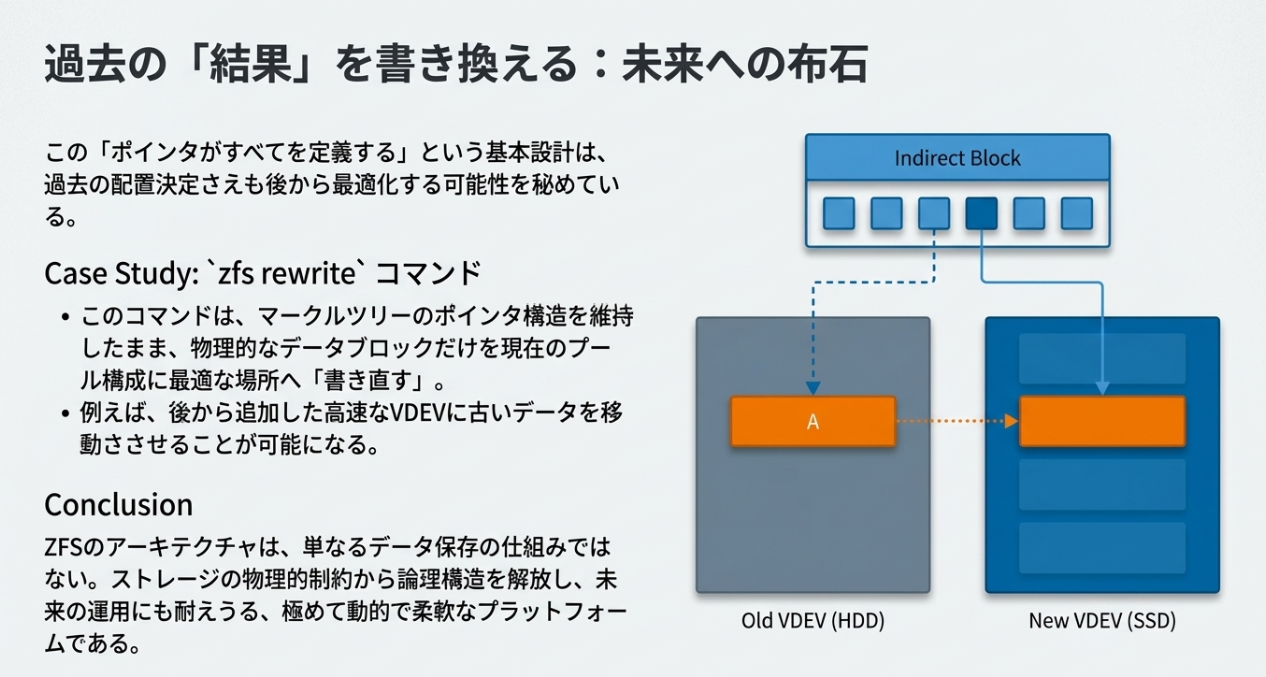
さらに、最新の zfs rewrite コマンドは、この柔軟な構造を維持したまま、物理的な配置だけを最新の構成に合わせて「書き直す」ことで、運用中の最適化すら可能にしています。
固定概念を打ち破る「動的なツリー構造」と「徹底した冗長化」。 これが、ZFSが「最後のファイルシステム」と呼ばれる理由だと思います。
こちらの論文を参考にさせていただいています。タイミング的には、OpenSolarisのZFSを対象に解析しているものと推測しますが、OpenZFSでも基本的な思想は引き継がれているものと推測します。
Reliability Analysis of ZFS https://pages.cs.wisc.edu/~kadav/zfs/zfsrel.pdf (Asim Kadav / Abhishek Rajimwale @ University of Wisconsin-Madison)
ZFS自体が非常に厳格にデータの書き込みアドレスまで管理しており、その後の書き換えなども基本的には行わないので、意図せずデータが書き換えられてしまうSMRのHDDとは相性が悪い気がします。(RAID系のデバイスはすべてSMRと相性よくないと思いますが)
BTRFSとはまた異なるアプローチのファイルシステムで、システム的な美しさを感じました。
間違っている部分があれば瀧さんからツッコミが入りそうな気がします・・・
でわでは