Categories

Blog posts about QNAP's products and technologies.
社内のハードドライブ、外付けのドライブ、あるいは NAS でも、時間が経つにつれて重複ファイルはほぼ必ず発生します。これは個人利用でも同様ですが、複数ユーザー環境ではさらに顕著です。重複ファイルが増え続けると、ストレージ領域を無駄に消費し、バックアップの速度を低下させ、最悪の場合データのリスクにもつながります。
本当にそんなに深刻なのでしょうか?いくつか簡単な例を見てみましょう。
1. 写真撮影後、カメラのメモリーカードから NAS に写真をコピーしたものの、カードのフォーマットを忘れてしまいます。次回新しい写真を撮影した際、再びメモリーカード全体を NAS にコピーします。ファイルが重複していることに気づかない場合や、すでに転送済みか覚えていない場合、同じドライブに重複ファイルが保存されてしまいます。これではバックアップ時のヘルプにはほとんど役立ちません。
2. マーケティング部門の展示会担当者が、ブース用のキービジュアル画像をフォルダー A に保存します。同じ部門のデザイナーも作業しやすいように同じ画像をフォルダー B に保存します。さらに外部のデザイン会社にファイルを渡す際、同じファイルを新たなフォルダーに保存して共有します。結果として、ハードドライブ内に同じファイルが 3 つ存在することになります。その 1 週間後、経験豊富な MIS チームが設定した 3 -2-1-1- 0 バックアップ戦略が実行され、これらの重複ファイルがさらに何度もバックアップされてしまいます。
上記の 2 つのケースはいずれも非常によくあることです。ストレージ領域や時間を無駄にするだけでなく、重複ファイルが多すぎるとバージョン管理が困難になります。時間が経つにつれて、どのファイルが同じものか分からなくなり、誤って削除してしまい、有効なコピーが残らない事態にもつながります。
そのため、定期的にファイルを整理する習慣は、時間とストレージの両方を節約するうえで効果的です。ただし、ファイルを一つずつ確認するのは非常に手間がかかるため、サードパーティ製のツールを活用するのが最適です。
名前付けが適切でないと、説明も分かりにくくなります。まずは作業内容を明確にしましょう。今回は NAS 上で、まったく同じファイルや写真を探すことが目的です。「類似写真の検索」に特化したアプリもありますが、それは全く別の作業であり、今回は扱いません。
まったく同じ写真を特定する場合、写真はハードドライブ上のファイルとして存在するため、内容が同一のファイルは基本的に同じ画像です。したがって、作業の本質的な目的は「重複ファイルを見つけること」となります。この作業は一般的に「重複排除(デデュプリケーション)」と呼ばれます。
ここで課題となるのは、どのようにしてそれらを見つけて比較するかです。多くのツールは基本的に同じアルゴリズムやロジックに従っており、一般的には次のような流れで処理されます。
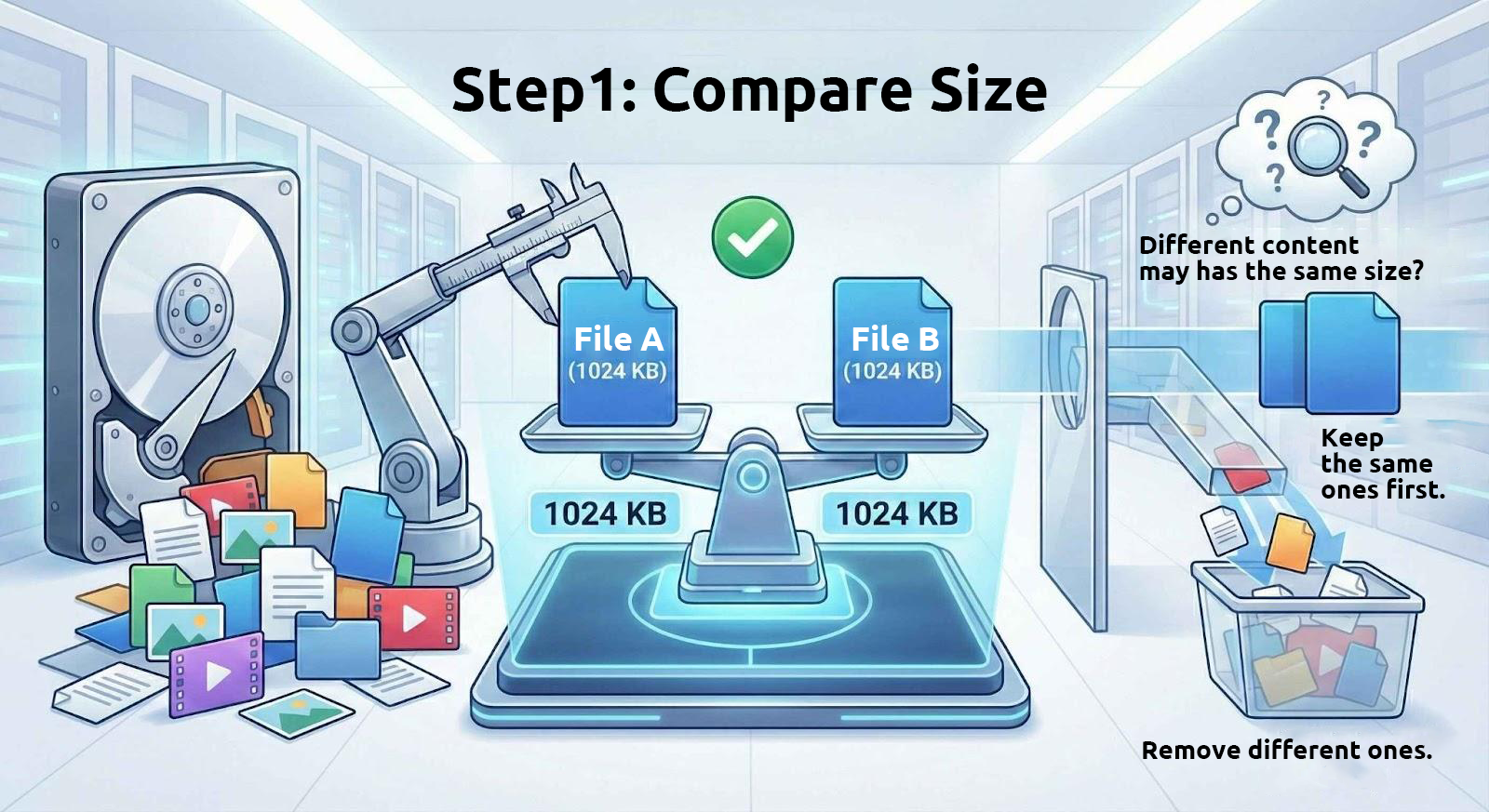
1. まずファイルサイズを比較する
内容が同じファイルは必ずサイズも同じです。そのため、これらのツールはまずドライブからサイズが同じファイルを抽出します。
ただし、サイズが同じでも内容が同一とは限りません。たとえば、分割アーカイブファイルは一定サイズごとに分割されますし、文字数が同じテキストファイルもサイズが一致します。したがって、ファイルサイズだけで同一かどうかを判断するのは、あくまで最初のステップに過ぎません。
2. 次にファイルの「指紋」を比較する
デジタルファイルはバイナリ形式で保存されているため、各ファイルの内容から数学的アルゴリズムを使って「ハッシュ値」と呼ばれる固有の 16 進数文字列を生成できます。アルゴリズムによって生成されるハッシュ値は異なります。計算量の多いアルゴリズム(例:SHA-512)は信頼性が高いですが時間がかかり、計算量の少ないアルゴリズム(例:MD5)は高速ですが信頼性が低くなります。
ファイルが異なれば、通常これらのハッシュ値が一致することはほとんどありません。これをより技術的には「衝突」と呼びますが、違いは偽造のしやすさだけです。ハッシュ値は各ファイルの固有の指紋と考えられます。2 つのファイルの指紋が一致すれば、それらは同一のファイルです。
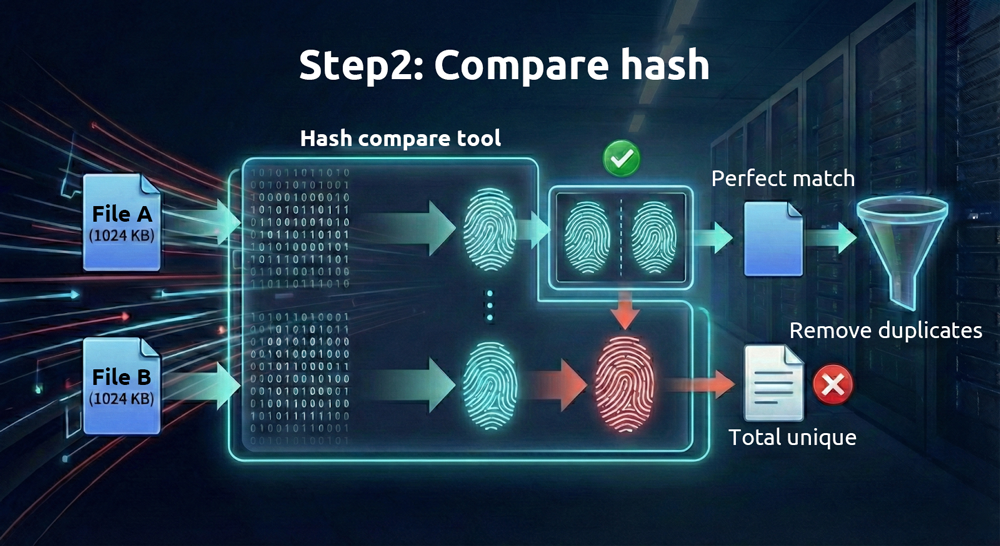
ハッシュ値の比較は非常に信頼性が高いですが、なぜ最初にファイルサイズを確認する必要があるのでしょうか?それはヘルプ時間とリソースの節約につながるからです。ハッシュ値の比較は計算負荷が高いですが、ファイルサイズの一致確認は現代のコンピューターにとってほとんど負担になりません。まずサイズで候補を絞り込んでからハッシュ値を比較することで、全体の処理効率が大幅に向上します。
Windows や macOS の多くのデスクトップアプリケーションでこの作業が可能です。ただし、ファイルがすでに NAS 上にある場合は、NAS 自体で直接処理を実行することで大幅な時間短縮が可能です。主な理由は 2 つあります:
1. ネットワーク転送時間
ハッシュ値の計算には、各ファイルの全内容を読み取る必要があります。ローカルコンピューターから NAS ファイルを頻繁に読み込むのは非効率的です。
2. ネイティブツールのサポート
NAS デバイスには、一般的にシンプルな重複排除ツールが標準搭載されていません(QNAP HBS ではバックアップタスク向けに重複排除機能が提供されていますが、これは別の記事で解説します)。ただし、Linux ユーティリティには、この作業を実現できるものが多数存在します。
QNAP の NAS では、まず SSH を有効にしてリモートでコマンドラインにログインします。その後、QPKG 経由で jdupes ユーティリティをインストールします。なお、jdupes は QNAP 公式のユーティリティではありません。セキュリティ上の懸念がある場合は、Docker 環境内で作業することを推奨します。
jdupes のコマンドラインオプションは非常にシンプルです。たとえば、現在のディレクトリとそのすべてのサブディレクトリ内で重複ファイルを探すには、次のコマンドを使用します:
jdupes -r .
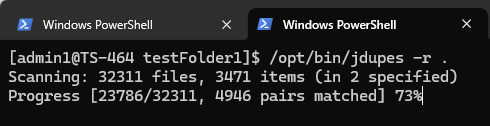
「-r」オプションは再帰的検索を意味し、「.」は現在のディレクトリから検索を開始することを示します。コマンドを実行すると、ユーティリティがファイル内容のスキャンを開始し、必要な時間はファイル数やサイズによって異なります。このツールは NAS 内のドライブを頻繁に読み込むため、ソリッドステートドライブ(SSD)上で実行すると、より高速です。
比較が完了すると、ユーティリティはすべての重複ファイルをグループごとに一覧表示します。以下のような形です:
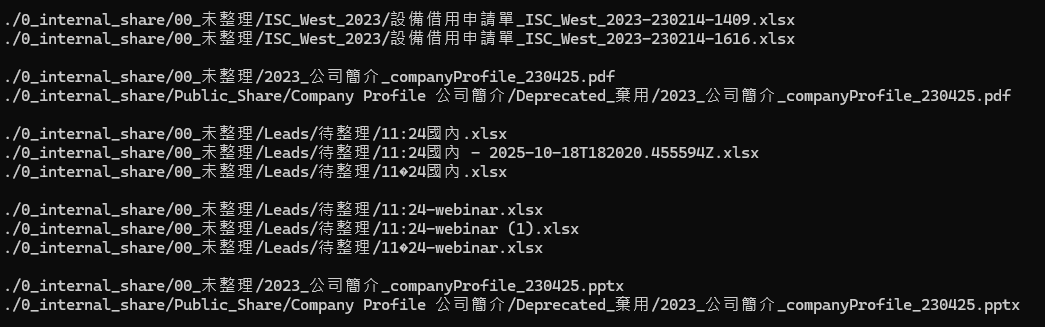
名前やパスが異なる多くのファイルが、実質的に同一であることに気づくでしょう。重複ファイルを特定したら、次はそれらを削除します。先ほどのコマンドに「d」を追加します。例:
Jdupes -rd .
結果を表示する際、ユーティリティはどのファイルを残すかユーザーに選択を促し、残りは削除されます。この方法はファイル数が少ない場合は問題ありませんが、数千もの重複セットがある場合、1 つずつ確認するのは現実的ではありません。
この場合は、コマンドに「N」を追加できます。例:
Jdupes -rdN .
「N」は「確認せず、最初に見つかった重複ファイルのみを残し、他は自動的に削除する」という意味です。このコマンドを実行すると、ターゲットディレクトリ内の同一ファイルは 1 つだけ残り、重複が効果的に解消されます。

上記の図では、「+」が付いたファイルは保持され、「-」が付いたファイルは削除されます。
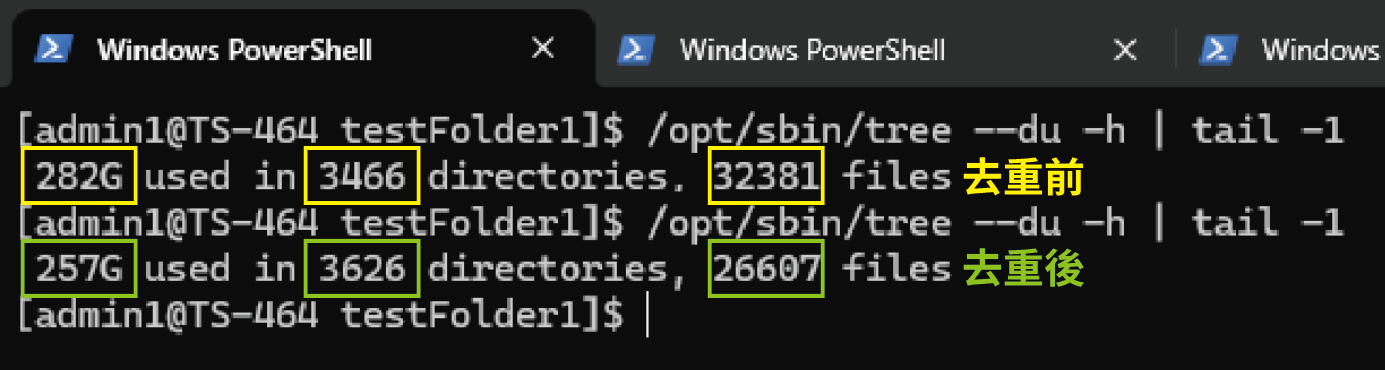
本記事のテストでは、元のディレクトリは合計 282GB ・ 32,381 ファイルでした。重複排除後、合計サイズは 8〜17% 削減されました。ディレクトリは TS-464 内の SSD 上にあり、全処理は約 30 秒で完了しました。これにより大幅な空き容量が確保でき、バックアップ時間も大幅に短縮されました。
この時点で、「特定のディレクトリ内のファイルは残したい場合は?」「重要なディレクトリのファイルは削除されないの?」と疑問に思う方もいるでしょう。
例えば、C:\Important 内のファイルを残したい場合は、以下のコマンドを使用します。
jdupes -rdN -X “path:Important” .
パスに「Important」を含むファイルは削除対象から除外されます。
重複ファイルの整理は、ディスク容量を数 GB 空けるだけでなく、デジタル環境の断捨離とも言えます。jdupes のような高性能ツールを使えば、従来は数日かかった手作業の比較も自動化で数分に短縮可能です。これにより NAS のストレージ効率が大幅に向上し、バックアップ作業もスムーズになり、3-2-1-1- 0 バックアップ戦略下で全てのデータが唯一無二の価値を持つことを保証できます。
定期的な整理習慣と適切なツールの活用により、NAS は真の「ハイパフォーマンスデータセンター」として機能し、ストレージを最大限に活用できます。