Categories

Blog posts about QNAP's products and technologies.
Che si tratti di un disco rigido interno, di un unità esterno o di un NAS, i file duplicati sono quasi inevitabili col tempo. Questo vale per gli utenti singoli—e ancora di più nelle configurazioni multiutente. Col tempo, questi file duplicati continueranno a crescere, sprecando Spazio di archiviazione, rallentando i backup e potenzialmente mettendo a rischio il tuo dati.
È davvero così grave? Vediamo alcuni semplici esempi.
1. Dopo una sessione fotografica, un fotografo copia le foto dalla scheda di memoria della fotocamera al NAS ma si dimentica di formattare la scheda. La volta successiva che scatta nuove foto, copia di nuovo l’intera scheda di memoria sul NAS. Che si accorga che i file sono duplicati o semplicemente non ricordi cosa è già stato trasferito, copie duplicate finiscono sullo stesso unità, il che non aiuta a Guida con i backup.
2. Un coordinatore di esposizione nel reparto marketing salva un’immagine visuale chiave per uno stand nella Cartella A. Un designer dello stesso reparto salva anche una copia della stessa immagine nella Cartella B per facilitare il proprio lavoro. Successivamente, quando consegna i file a un’agenzia di design esterna, crea un’altra cartella per archiviare lo stesso file così che l’agenzia possa accedervi. Alla fine, il disco rigido finisce per contenere tre copie dello stesso file. Una settimana dopo, la strategia di backup 3-2-1-1-0, impostata dal team MIS esperto, entra in azione, facendo sì che questi file duplicati vengano salvati più volte.
Entrambi gli scenari sopra descritti sono molto comuni. Oltre a sprecare Spazio di archiviazione e tempo, avere troppi file duplicati può rendere difficile la gestione delle versioni. Col tempo, può diventare complicato capire quali file siano identici, e questo può persino portare a cancellazioni accidentali—senza lasciare alcuna copia valida.
Pertanto, pulire regolarmente i propri file è una buona abitudine per risparmiare sia tempo che Archiviazione. Tuttavia, controllare i file uno per uno può richiedere molto tempo, quindi è meglio utilizzare strumenti di terze parti per svolgere il lavoro.
Se le cose non sono nominate correttamente, le spiegazioni non avranno senso. Prima di procedere, chiariamo il compito: stiamo cercando file e foto su NAS che siano duplicati esatti. Alcune applicazioni si concentrano sul “trovare foto simili”, ma questo è un tipo di compito completamente diverso, di cui possiamo parlare un’altra volta.
Per quanto riguarda l’identificazione di foto esattamente identiche, poiché le foto esistono su un disco rigido come file, qualsiasi file con contenuto identico è essenzialmente la stessa immagine. Questo ci permette di semplificare l’obiettivo principale del compito: basta trovare i file duplicati. Questo processo è comunemente chiamato “deduplicazione”.
Ecco la sfida: come trovarli e confrontarli? La maggior parte degli strumenti segue lo stesso algoritmo e logica di base, che generalmente funziona come segue:
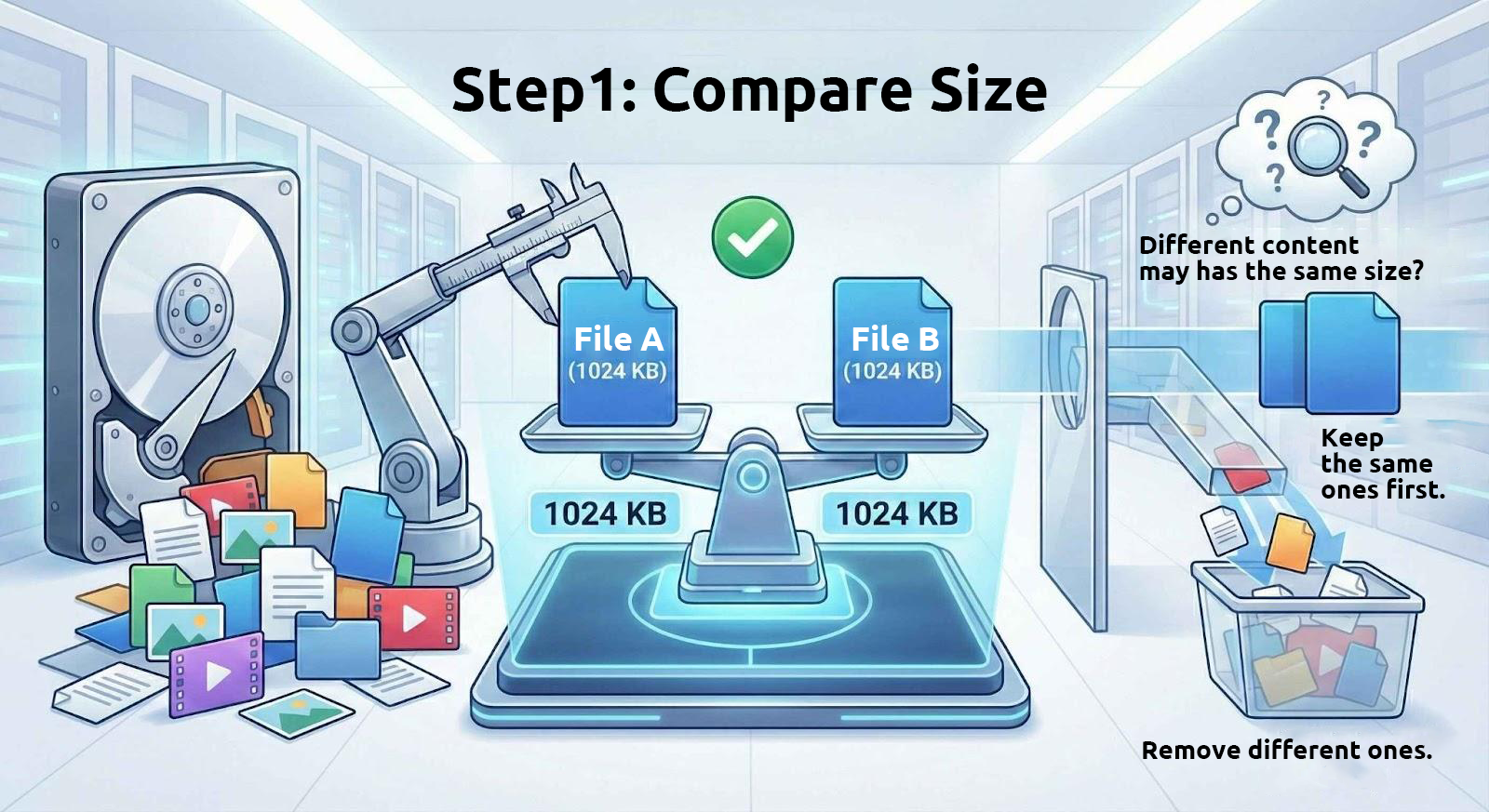
1. Confronta prima le dimensioni dei file
I file con contenuto identico hanno sempre la stessa dimensione. Pertanto, questi strumenti iniziano filtrando i file di dimensioni identiche da unità.
Tuttavia, file con la stessa dimensione non hanno necessariamente contenuto identico. Ad esempio, molti file di archivio suddivisi sono divisi in parti di dimensione fissa, e i file di testo con lo stesso numero di caratteri avranno anch’essi la stessa dimensione. Quindi, usare solo la dimensione del file per determinare se i file sono identici è solo il primo passo.
2. Quindi confronta le “impronte digitali” dei file
Poiché i file digitali sono memorizzati in formato binario, da ciascun file può essere generata una stringa esadecimale unica—chiamata “valore hash”—utilizzando algoritmi matematici. Algoritmi diversi producono valori hash diversi. Gli algoritmi che richiedono più calcoli (come SHA-512) sono più affidabili ma più lenti, mentre quelli che richiedono meno calcoli (come MD5) sono più veloci ma meno affidabili.
Finché i file sono diversi, questi valori hash, in condizioni normali, difficilmente saranno identici. Un termine più tecnico per questo è “collisione”; l’unica differenza è quanto facilmente possano essere falsificati. Possiamo considerare un valore hash come un’impronta digitale unica per ogni file. Se due file hanno impronte digitali identiche, sono identici.
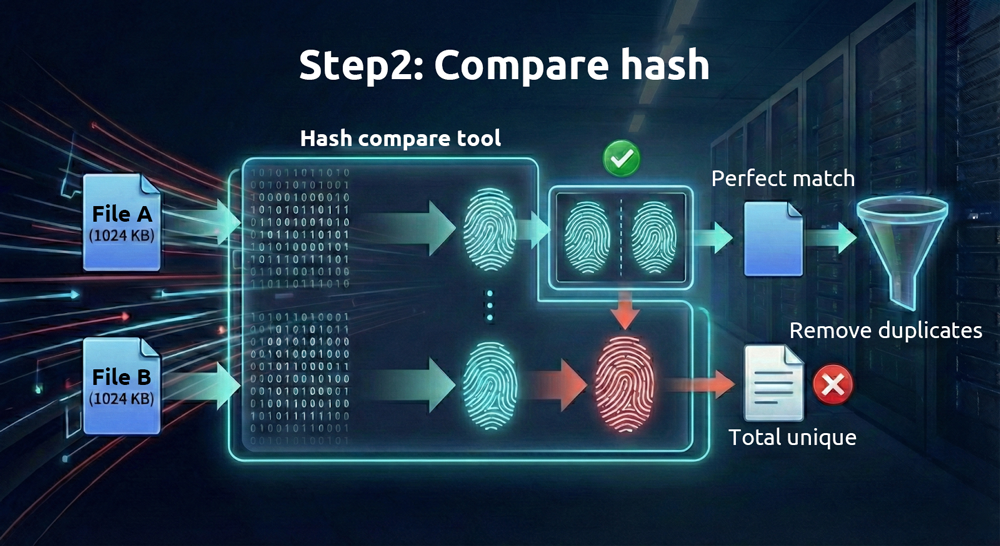
Data l’elevata affidabilità del confronto degli hash, perché è comunque necessario controllare prima le dimensioni dei file? Farlo Guida consente di risparmiare tempo e risorse. Il confronto dei valori hash è computazionalmente intensivo, ma identificare file con dimensioni identiche è quasi immediato per i computer moderni. Riducendo prima il numero di file in base alla dimensione prima di confrontare gli hash, il processo diventa molto più efficiente.
Molte applicazioni desktop su Windows e macOS possono gestire questo compito. Tuttavia, se i file sono già su un NAS, eseguire il processo direttamente sul NAS stesso può far risparmiare molto tempo. Ci sono due motivi principali per questo:
1. Tempo di trasferimento in rete
Il calcolo dei valori hash richiede la lettura completa del contenuto di ogni file. Eseguire letture frequenti di file NAS da un computer locale è inefficiente.
2. Supporto degli strumenti nativi
Sebbene i dispositivi NAS generalmente non dispongano di semplici strumenti di deduplicazione integrati (QNAP HBS offre la deduplicazione per le attività di backup, che verrà discussa in un articolo futuro), esistono numerose utility Linux che possono svolgere questo compito.
Su un QNAP NAS, prima abilita SSH e accedi alla riga di comando da remoto. Poi, installa l’utility jdupes tramite QPKG. Nota che jdupes non è un’utility ufficiale QNAP; se ci sono preoccupazioni relative a Sicurezza, è consigliabile eseguire queste operazioni all’interno di un ambiente Docker.
Le opzioni della riga di comando per jdupes sono piuttosto semplici. Ad esempio, per individuare file duplicati nella directory corrente, inclusi tutti i sottodirectory, usa il seguente comando:
jdupes -r .
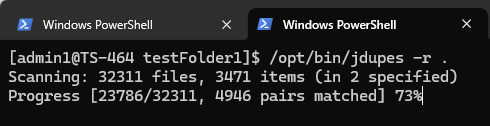
L’opzione “-r” indica la modalità ricorsiva, e “.” significa che la ricerca parte dalla directory corrente. Una volta eseguito, l’utility inizia a scansionare il contenuto dei file e il tempo richiesto dipende dal numero e dalla dimensione dei file. Poiché questo strumento legge frequentemente dal unità all’interno del NAS, eseguirlo su un unità a stato solido (SSD) sarà molto più veloce.
Una volta terminato il confronto, l’utility elenca tutti i file duplicati e li organizza in gruppi, come mostrato di seguito:
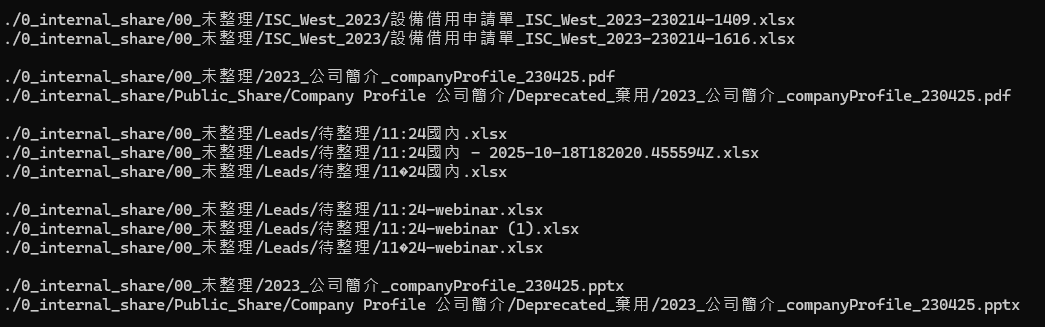
Noterai che molti file con nomi o percorsi diversi sono essenzialmente identici. Dopo aver identificato i file duplicati, il passo successivo è eliminarli. Aggiungi “d” al comando precedente, ad esempio:
Jdupes -rd .
Quando visualizza i risultati, l’utility chiede all’utente quale file mantenere; gli altri vengono eliminati. Questo metodo funziona bene per un numero ridotto di file, ma quando si tratta di grandi quantità—ad esempio, migliaia di set duplicati—non è pratico confermare ciascuno singolarmente.
A questo punto, puoi aggiungere “N” al comando, come segue:
Jdupes -rdN .
La “N” significa “Non chiedere, mantieni semplicemente il primo file corrispondente trovato” e tutti gli altri verranno eliminati automaticamente. Dopo aver eseguito questo comando, rimarrà solo una copia di ciascun file identico nella directory di destinazione, deduplicandola efficacemente.

Nella figura sopra, i file con il prefisso “+” vengono mantenuti, mentre quelli con il prefisso “-” vengono eliminati.
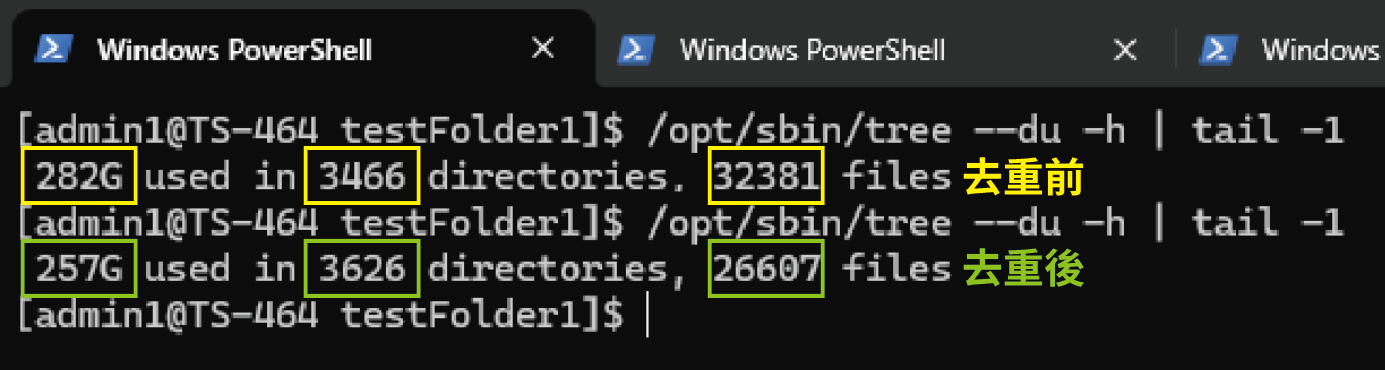
Nel nostro test per questo articolo, la directory originale aveva un totale di 282 GB e conteneva 32.381 file. Dopo la deduplicazione, la dimensione totale è stata ridotta dell’8–17%. La directory si trovava su un SSD nel TS-464 e l’intera operazione ha richiesto circa 30 secondi. Dopo l’operazione, non solo è stato risparmiato un notevole spazio, ma anche i tempi di backup sono risultati molto più rapidi.
A questo punto, alcuni utenti potrebbero chiedersi: “E se volessi mantenere i file in una directory specifica?” oppure “Sicuramente i file nelle directory importanti non dovrebbero essere eliminati, giusto?”
Ad esempio, per mantenere i file in C:\Important, puoi usare il seguente comando:
jdupes -rdN -X “path:Important” .
I file con percorsi contenenti “Important” saranno esclusi dall’eliminazione.
Eliminare i file duplicati non serve solo a liberare qualche gigabyte di spazio disco; può essere visto come una forma di decluttering digitale. Con strumenti ad alte prestazioni come jdupes, il confronto manuale che una volta richiedeva giorni può essere completato in pochi minuti grazie all’automazione. Questo aumenta notevolmente l’efficienza di NAS Archiviazione, semplifica il processo di backup e garantisce che ogni elemento di dati nella strategia di backup 3-2-1-1-0 rimanga unico e prezioso.
Coltivando l’abitudine di una pulizia regolare e utilizzando gli strumenti giusti, un NAS può davvero funzionare come un “centro dati ad alte prestazioni”, assicurando che ogni bit di Archiviazione venga utilizzato al meglio.