Categories

Blog posts about QNAP's products and technologies.
Niezależnie od tego, czy jest to wewnętrzny twardy dysk, zewnętrzny dysk, czy Serwer NAS, zduplikowane pliki są niemal nieuniknione z biegiem czasu. Dotyczy to użytkowników indywidualnych — a jeszcze bardziej środowisk wieloużytkownikowych. Z czasem te zduplikowane pliki będą się mnożyć, marnując Przestrzeń dyskowa, spowalniając kopie zapasowe i potencjalnie narażając Twój dane na ryzyko.
Czy to naprawdę aż tak poważne? Przyjrzyjmy się kilku prostym przykładom.
1. Po sesji zdjęciowej fotograf kopiuje zdjęcia z karty pamięci aparatu na Serwer NAS, ale zapomina sformatować kartę. Następnym razem, gdy robi nową serię zdjęć, ponownie kopiuje całą kartę pamięci na Serwer NAS. Niezależnie od tego, czy zauważy, że pliki się powielają, czy po prostu nie pamięta, co już zostało przeniesione, duplikaty trafiają na ten sam dysk, co niewiele pomaga w Pomoc kopii zapasowych.
2. Koordynator wystawy w dziale marketingu zapisuje kluczowy obraz wizualny stoiska w folderze A. Projektant z tego samego działu również zapisuje kopię tego samego obrazu w folderze B, aby ułatwić sobie pracę. Później, przekazując pliki zewnętrznej agencji projektowej, tworzą kolejny folder na ten sam plik, aby agencja miała do niego dostęp. W rezultacie twardy dysk zawiera trzy kopie tego samego pliku. Tydzień później uruchamia się strategia backupu 3-2-1-1-0, skonfigurowana przez doświadczony zespół MIS, co skutkuje tym, że te zduplikowane pliki są kopiowane zapasowo jeszcze kilka razy.
Oba powyższe scenariusze są bardzo powszechne. Oprócz marnowania Przestrzeń dyskowa i czasu, zbyt duża liczba zduplikowanych plików może utrudniać zarządzanie wersjami. Z czasem może być trudno stwierdzić, które pliki są identyczne, co może nawet prowadzić do przypadkowego usunięcia—nie pozostawiając żadnej ważnej kopii.
Dlatego regularne porządkowanie plików to dobry nawyk, który pozwala zaoszczędzić zarówno czas, jak i Pamięć masowa. Jednak przeglądanie plików jeden po drugim może być bardzo czasochłonne, dlatego najlepiej skorzystać z narzędzi firm trzecich, aby wykonać to zadanie.
Jeśli rzeczy nie są odpowiednio nazwane, wyjaśnienia nie będą miały sensu. Zanim przejdziemy dalej, wyjaśnijmy zadanie: szukamy plików i zdjęć na Serwer NAS, które są dokładnymi duplikatami. Niektóre aplikacje skupiają się na „wyszukiwaniu podobnych zdjęć”, ale to zupełnie inny rodzaj zadania, o którym możemy porozmawiać innym razem.
Jeśli chodzi o identyfikację dokładnie takich samych zdjęć, ponieważ zdjęcia istnieją na twardy dysk jako pliki, wszelkie pliki o identycznej zawartości są w istocie tym samym obrazem. Pozwala to uprościć główny cel zadania: po prostu znaleźć zduplikowane pliki. Proces ten jest powszechnie określany jako „deduplikacja”.
Oto wyzwanie: jak je znaleźć i porównać? Większość narzędzi stosuje ten sam podstawowy algorytm i logikę, która zazwyczaj wygląda następująco:
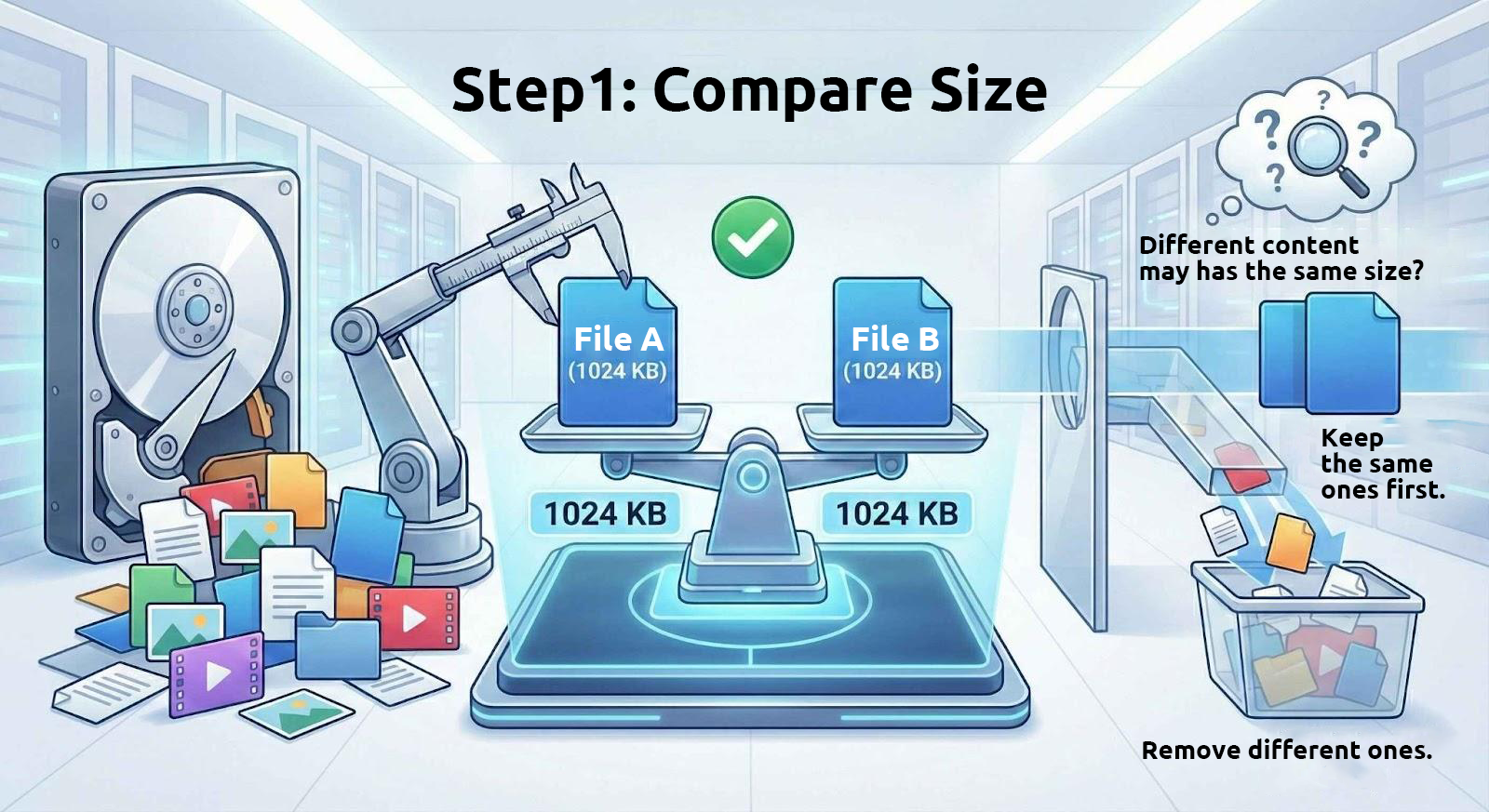
1. Najpierw porównaj rozmiary plików
Pliki o identycznej zawartości zawsze mają ten sam rozmiar. Dlatego te narzędzia zaczynają od filtrowania plików o identycznym rozmiarze z dysk.
Jednak pliki o tym samym rozmiarze niekoniecznie mają identyczną zawartość. Na przykład wiele podzielonych archiwów jest dzielonych na części o stałym rozmiarze, a pliki tekstowe z taką samą liczbą znaków również będą miały ten sam rozmiar. Dlatego używanie wyłącznie rozmiaru pliku do określenia, czy pliki są identyczne, to tylko pierwszy krok.
2. Następnie porównaj „odciski palców” plików
Ponieważ pliki cyfrowe są przechowywane w postaci binarnej, z zawartości każdego pliku można wygenerować unikalny ciąg szesnastkowy — zwany „wartością skrótu” — za pomocą algorytmów matematycznych. Różne algorytmy generują różne wartości skrótu. Algorytmy wymagające większej mocy obliczeniowej (takie jak SHA-512) są bardziej niezawodne, ale działają wolniej, natomiast te wymagające mniej obliczeń (takie jak MD5) są szybsze, ale mniej niezawodne.
Dopóki pliki się różnią, te wartości skrótu, w normalnych warunkach, bardzo rzadko będą identyczne. Bardziej technicznym określeniem tego zjawiska jest „kolizja”; jedyna różnica polega na tym, jak łatwo można je sfałszować. Wartość skrótu można traktować jako unikalny odcisk palca każdego pliku. Jeśli dwa pliki mają identyczne odciski palców, są identyczne.
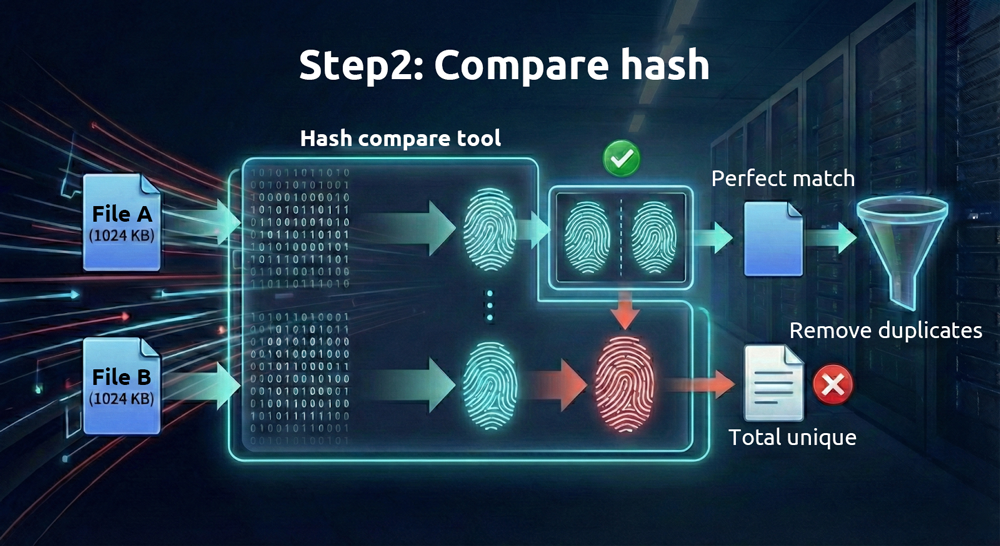
Biorąc pod uwagę wysoką niezawodność porównań skrótów, dlaczego nadal konieczne jest najpierw sprawdzenie rozmiarów plików? Robienie tego Pomoc pozwala zaoszczędzić czas i zasoby. Porównywanie wartości skrótu jest obciążające obliczeniowo, natomiast identyfikacja plików o identycznych rozmiarach jest dla współczesnych komputerów niemal bezwysiłkowa. Najpierw zawężając liczbę plików na podstawie rozmiaru przed porównaniem skrótów, proces staje się znacznie wydajniejszy.
Wiele aplikacji desktopowych na Windows i macOS potrafi wykonać to zadanie. Jednak jeśli pliki znajdują się już na Serwer NAS, uruchomienie procesu bezpośrednio na samym Serwer NAS może zaoszczędzić sporo czasu. Istnieją dwa główne powody:
1. Czas transferu przez sieć
Obliczanie wartości skrótu wymaga odczytania całej zawartości każdego pliku. Częste odczytywanie plików Serwer NAS z lokalnego komputera jest nieefektywne.
2. Wsparcie dla natywnych narzędzi
Chociaż urządzenia Serwer NAS zazwyczaj nie posiadają prostych, wbudowanych narzędzi do deduplikacji (QNAP HBS oferuje deduplikację dla zadań backupu, co zostanie omówione w przyszłym artykule), istnieje szeroki wybór narzędzi Linux, które mogą wykonać to zadanie.
Na urządzeniu QNAP Serwer NAS najpierw włącz SSH i zaloguj się zdalnie do wiersza poleceń. Następnie zainstaluj narzędzie jdupes za pomocą QPKG. Zwróć uwagę, że jdupes nie jest oficjalnym narzędziem QNAP; jeśli istnieją jakiekolwiek obawy dotyczące Zabezpieczenia, zaleca się wykonywanie tych czynności w środowisku Docker.
Opcje wiersza poleceń dla jdupes są dość proste. Na przykład, aby znaleźć zduplikowane pliki w bieżącym katalogu, wraz ze wszystkimi podkatalogami, użyj następującego polecenia:
jdupes -r .
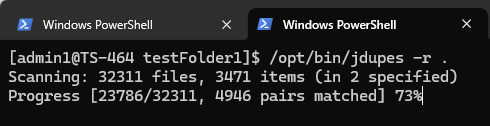
Opcja „-r” oznacza rekurencję, a „.” oznacza, że wyszukiwanie rozpoczyna się od bieżącego katalogu. Po uruchomieniu narzędzie zaczyna skanować zawartość plików, a wymagany czas zależy od liczby i rozmiaru plików. Ponieważ to narzędzie często odczytuje z dyski wewnątrz Serwer NAS, uruchomienie go na dysku półprzewodnikowym dysk (SSD) będzie znacznie szybsze.
Po zakończeniu porównania narzędzie wyświetli wszystkie zduplikowane pliki i pogrupuje je w zestawy, jak pokazano poniżej:
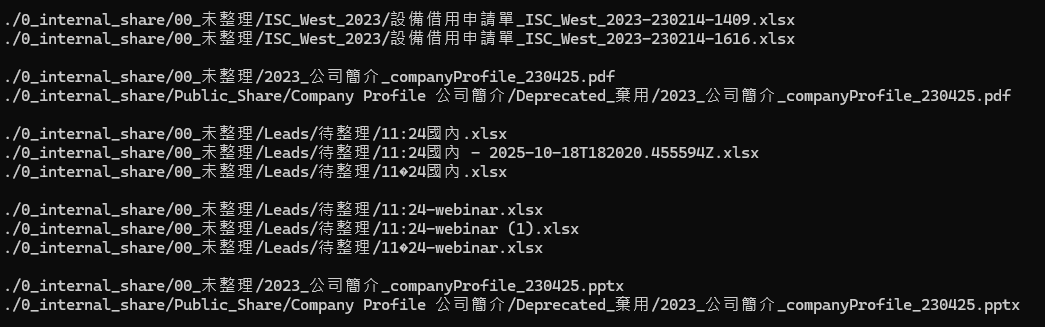
Zauważysz, że wiele plików o różnych nazwach lub ścieżkach jest w rzeczywistości identycznych. Po zidentyfikowaniu zduplikowanych plików kolejnym krokiem jest ich usunięcie. Dodaj „d” do poprzedniego polecenia, na przykład:
Jdupes -rd .
Podczas wyświetlania wyników narzędzie prosi użytkownika o wybranie pliku do zachowania; pozostałe są usuwane. Ta metoda sprawdza się przy niewielkiej liczbie plików, ale w przypadku dużych ilości—na przykład tysięcy zestawów duplikatów—potwierdzanie każdego z osobna jest niepraktyczne.
W tym momencie możesz dodać „N” do polecenia, w ten sposób:
Jdupes -rdN .
Opcja „N” oznacza „Nie pytaj, po prostu zachowaj pierwszy znaleziony pasujący plik”, a wszystkie pozostałe zostaną automatycznie usunięte. Po uruchomieniu tej komendy w docelowym katalogu pozostanie tylko jedna kopia każdego identycznego pliku, skutecznie eliminując duplikaty.

Na powyższym rysunku pliki z prefiksem „+” są zachowywane, a te z prefiksem „-” są usuwane.
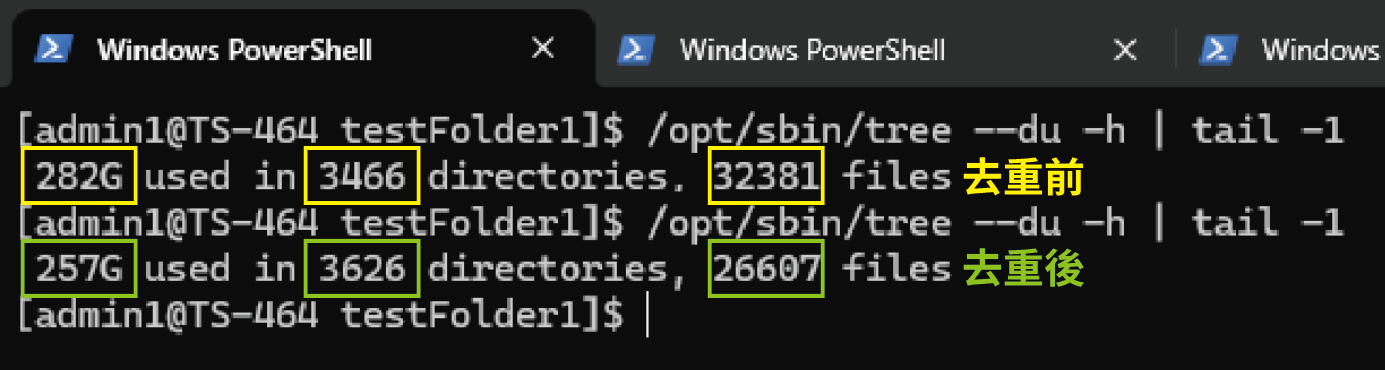
W naszym teście do tego artykułu oryginalny katalog miał łącznie 282 GB i zawierał 32 381 plików. Po deduplikacji całkowity rozmiar zmniejszył się o 8–17%. Katalog znajdował się na SSD w TS-464, a cała operacja trwała około 30 sekund. Po operacji nie tylko zaoszczędzono znaczną ilość miejsca, ale także czas tworzenia kopii zapasowych znacznie się skrócił.
W tym momencie niektórzy użytkownicy mogą się zastanawiać: „A co, jeśli chcę zachować pliki w określonym katalogu?” lub „Przecież pliki w ważnych katalogach nie powinny być usuwane, prawda?”
Na przykład, aby zachować pliki w C:\Important, można użyć następującej komendy:
jdupes -rdN -X „path:Important” .
Pliki ze ścieżkami zawierającymi „Important” zostaną wykluczone z usuwania.
Usuwanie zduplikowanych plików to nie tylko zwolnienie kilku gigabajtów przestrzeni dysk; można to traktować jako cyfrowe porządki. Dzięki wydajnym narzędziom takim jak jdupes, ręczne porównywanie, które kiedyś trwało dni, można zautomatyzować i wykonać w kilka minut. To znacząco zwiększa efektywność Serwer NAS Pamięć masowa, usprawnia proces tworzenia kopii zapasowych i zapewnia, że każda część dane w ramach strategii kopii zapasowych 3-2-1-1-0 pozostaje unikalna i wartościowa.
Dzięki wyrobieniu nawyku regularnego czyszczenia i używaniu odpowiednich narzędzi, Serwer NAS może naprawdę pełnić funkcję „wysokowydajnego centrum dane”, zapewniając optymalne wykorzystanie każdego bitu Pamięć masowa.