Categories

Blog posts about QNAP's products and technologies.
Ya sea un disco duro interno, un unidad externo o un NAS, los archivos duplicados son casi inevitables con el tiempo. Esto ocurre tanto en usuarios individuales como, aún más, en configuraciones multiusuario. Con el tiempo, estos archivos duplicados seguirán aumentando, desperdiciando Espacio de almacenamiento, ralentizando las copias de seguridad y, potencialmente, poniendo en riesgo su datos.
¿Realmente es tan grave? Veamos algunos ejemplos sencillos.
1. Tras una sesión de fotos, un fotógrafo copia las fotos de la tarjeta de memoria de la cámara al NAS pero olvida formatear la tarjeta. La siguiente vez que toma nuevas fotos, vuelve a copiar toda la tarjeta de memoria al NAS. Tanto si se da cuenta de que los archivos están duplicados como si simplemente no recuerda qué ya se transfirió, las copias duplicadas terminan en el mismo unidad, lo que aporta poco para Ayuda con las copias de seguridad.
2. Un coordinador de exposiciones del departamento de marketing guarda una imagen visual clave para un stand en la Carpeta A. Un diseñador del mismo departamento también guarda una copia de la misma imagen en la Carpeta B para facilitar su trabajo. Más tarde, al entregar archivos a una agencia de diseño externa, crean otra carpeta para almacenar el mismo archivo y que la agencia pueda acceder a él. Al final, el disco duro termina conteniendo tres copias del mismo archivo. Una semana después, la estrategia de copia de seguridad 3-2-1-1-0, configurada por el experimentado equipo de MIS, entra en acción, lo que provoca que estos archivos duplicados se respalden varias veces más.
Ambos escenarios anteriores son muy comunes. Además de desperdiciar Espacio de almacenamiento y tiempo, tener demasiados archivos duplicados puede dificultar la gestión de versiones. Con el tiempo, puede resultar complicado saber qué archivos son idénticos, lo que incluso puede llevar a un borrado accidental, dejando sin copia válida.
Por lo tanto, limpiar regularmente tus archivos es un buen hábito para ahorrar tanto tiempo como Almacenamiento. Sin embargo, revisar los archivos uno por uno puede llevar mucho tiempo, así que lo mejor es utilizar herramientas de terceros para realizar esta tarea.
Si las cosas no están correctamente nombradas, las explicaciones no tendrán sentido. Antes de continuar, aclaremos la tarea: estamos buscando archivos y fotos en el NAS que sean duplicados exactos. Algunas aplicaciones se centran en “encontrar fotos similares”, pero eso es un tipo de tarea completamente diferente, de la que podemos hablar en otro momento.
En cuanto a identificar fotos exactamente idénticas, dado que las fotos existen en un disco duro como archivos, cualquier archivo con contenido idéntico es esencialmente la misma imagen. Esto nos permite simplificar el objetivo principal de la tarea: simplemente encontrar archivos duplicados. Este proceso se conoce comúnmente como “deduplicación”.
Aquí viene el reto: ¿cómo encontrarlos y compararlos? La mayoría de las herramientas siguen el mismo algoritmo y lógica subyacentes, que generalmente funcionan de la siguiente manera:
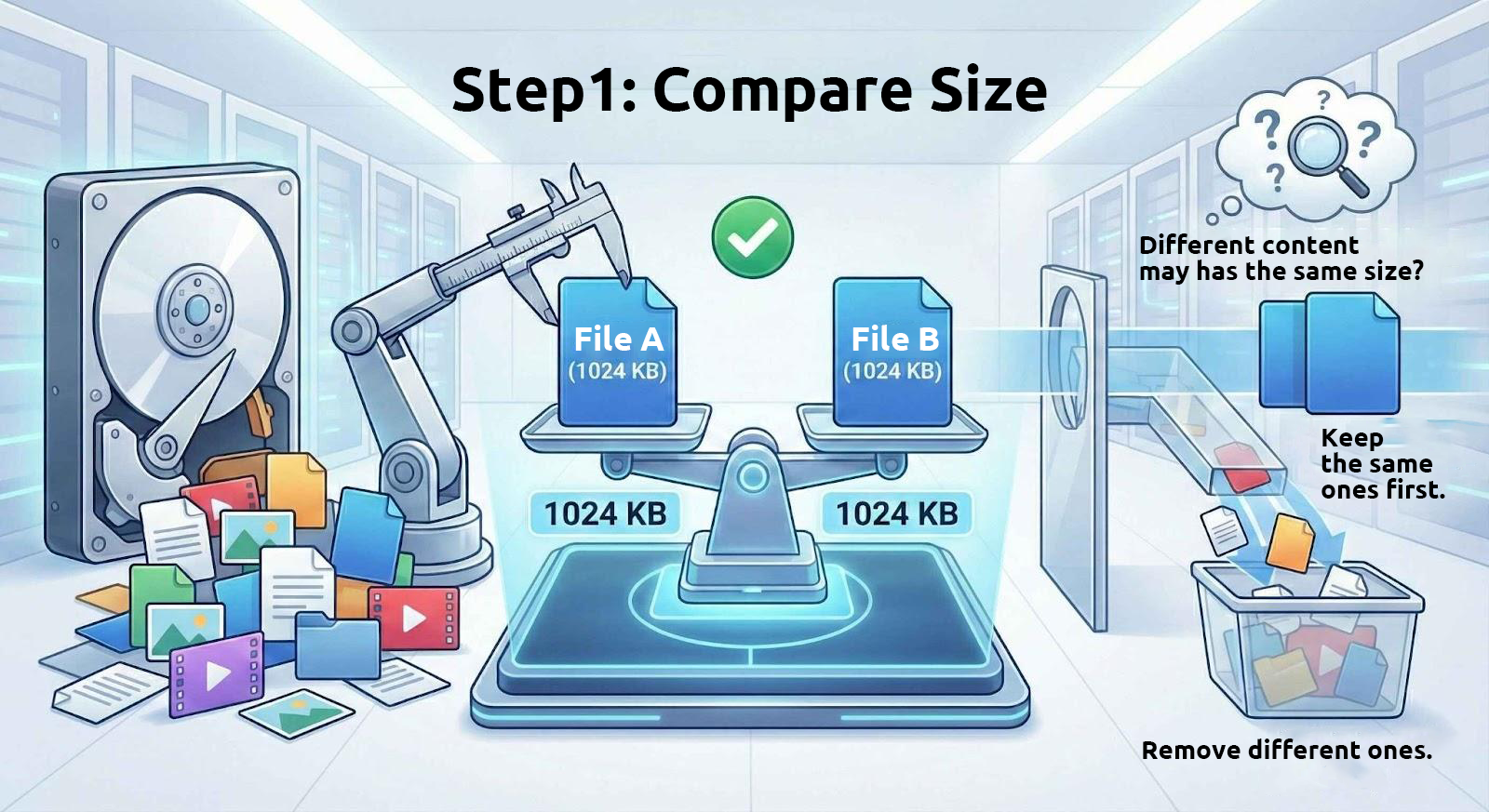
1. Comparar primero el tamaño de los archivos
Los archivos con contenido idéntico siempre tienen el mismo tamaño. Por lo tanto, estas herramientas comienzan filtrando los archivos de tamaño idéntico del unidad.
Sin embargo, los archivos con el mismo tamaño no necesariamente tienen el mismo contenido. Por ejemplo, muchos archivos comprimidos divididos se separan en partes de tamaño fijo, y los archivos de texto con el mismo número de caracteres también tendrán el mismo tamaño. Por lo tanto, usar solo el tamaño del archivo para determinar si los archivos son idénticos es solo el primer paso.
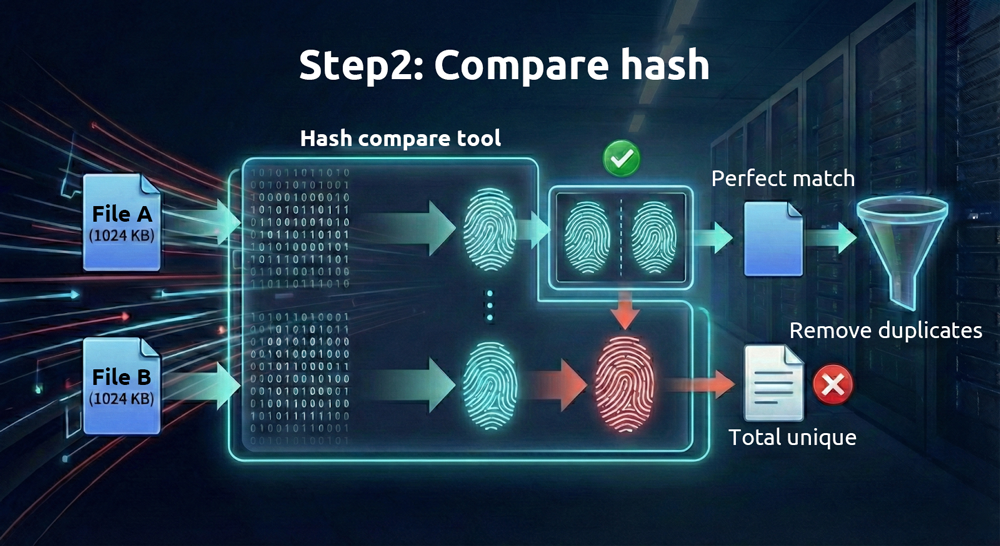
2. Después, compare las “huellas digitales” de los archivos
Como los archivos digitales se almacenan en formato binario, se puede generar una cadena hexadecimal única—llamada “valor hash”—a partir del contenido de cada archivo utilizando algoritmos matemáticos. Diferentes algoritmos producen diferentes valores hash. Los algoritmos que requieren más cálculos (como SHA-512) son más fiables pero tardan más tiempo, mientras que los que requieren menos cálculos (como MD5) son más rápidos pero menos fiables.
Mientras los archivos sean diferentes, estos valores hash, en circunstancias normales, es muy poco probable que sean idénticos. Un término más técnico para esto es “colisión”; la única diferencia es lo fácil que pueden ser falsificados. Podemos considerar un valor hash como una huella digital única para cada archivo. Si dos archivos tienen huellas digitales idénticas, son idénticos.
Dada la alta fiabilidad de las comparaciones de hash, ¿por qué sigue siendo necesario comprobar primero el tamaño de los archivos? Hacerlo Ayuda ahorra tiempo y recursos. Comparar valores hash requiere mucha computación, pero identificar archivos con tamaños idénticos es casi instantáneo para los ordenadores modernos. Al reducir primero el número de archivos según el tamaño antes de comparar los hash, el proceso se vuelve mucho más eficiente.
Muchas aplicaciones de escritorio en Windows y macOS pueden realizar esta tarea. Sin embargo, si los archivos ya están en un NAS, ejecutar el proceso directamente en el propio NAS puede ahorrar mucho tiempo. Hay dos razones principales para esto:
1. Tiempo de transferencia de red
Calcular los valores hash requiere leer el contenido completo de cada archivo. Realizar lecturas frecuentes de archivos NAS desde un ordenador local es ineficiente.
2. Compatibilidad con herramientas nativas
Aunque los dispositivos NAS generalmente no incluyen herramientas de deduplicación integradas sencillas (QNAP HBS sí ofrece deduplicación para tareas de copia de seguridad, lo que se tratará en un artículo futuro), existe una amplia variedad de utilidades Linux que pueden realizar esta tarea.
En un QNAP NAS, primero active SSH e inicie sesión en la línea de comandos de forma remota. Luego, instale la utilidad jdupes mediante QPKG. Tenga en cuenta que jdupes no es una utilidad oficial de QNAP; si existen preocupaciones de Seguridad, es recomendable realizar estas tareas dentro de un entorno Docker.
Las opciones de línea de comandos para jdupes son bastante sencillas. Por ejemplo, para localizar archivos duplicados en el directorio actual, incluyendo todos los subdirectorios, utilice el siguiente comando:
jdupes -r .
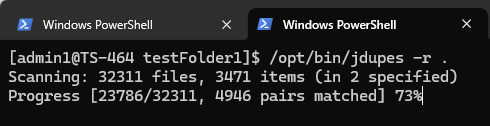
La opción “-r” significa recursivo, y el “.” indica que la búsqueda comienza en el directorio actual. Una vez ejecutada, la utilidad comienza a escanear el contenido de los archivos, y el tiempo requerido depende del número y tamaño de los archivos. Como esta herramienta lee frecuentemente desde el unidades dentro del NAS, ejecutarla en un unidad de estado sólido (SSD) será mucho más rápido.
Una vez finalizada la comparación, la utilidad muestra todos los archivos duplicados y los organiza en grupos, como se muestra a continuación:
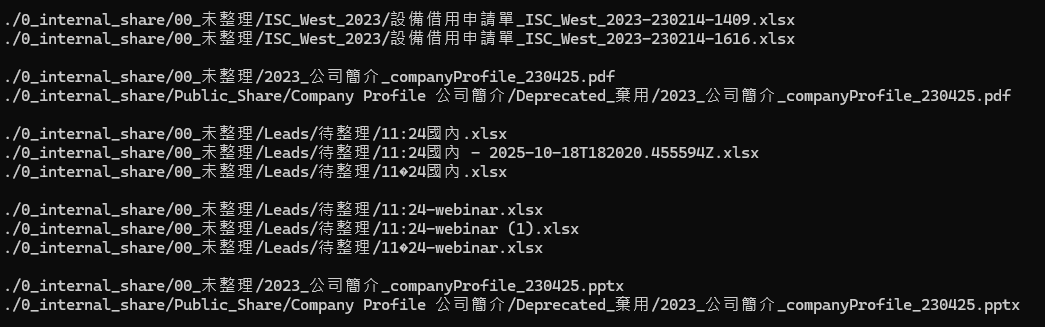
Notará que muchos archivos con diferentes nombres o rutas son, en esencia, idénticos. Tras identificar los archivos duplicados, el siguiente paso es eliminarlos. Añada “d” al comando anterior, por ejemplo:
Jdupes -rd .
Al mostrar los resultados, la utilidad solicita al usuario que seleccione qué archivo conservar; el resto se elimina. Este método funciona bien para un número reducido de archivos, pero cuando se trata de grandes cantidades—por ejemplo, miles de conjuntos duplicados—no es práctico confirmar cada uno individualmente.
En este punto, puede añadir “N” al comando, así:
Jdupes -rdN .
La opción “N” significa “No preguntar, simplemente conservar el primer archivo coincidente encontrado”, y todos los demás se eliminarán automáticamente. Tras ejecutar este comando, solo quedará una copia de cada archivo idéntico en el directorio de destino, deduplicándolo de manera efectiva.

En la figura anterior, los archivos con el prefijo “+” se conservan, mientras que los que tienen el prefijo “-” se eliminan.
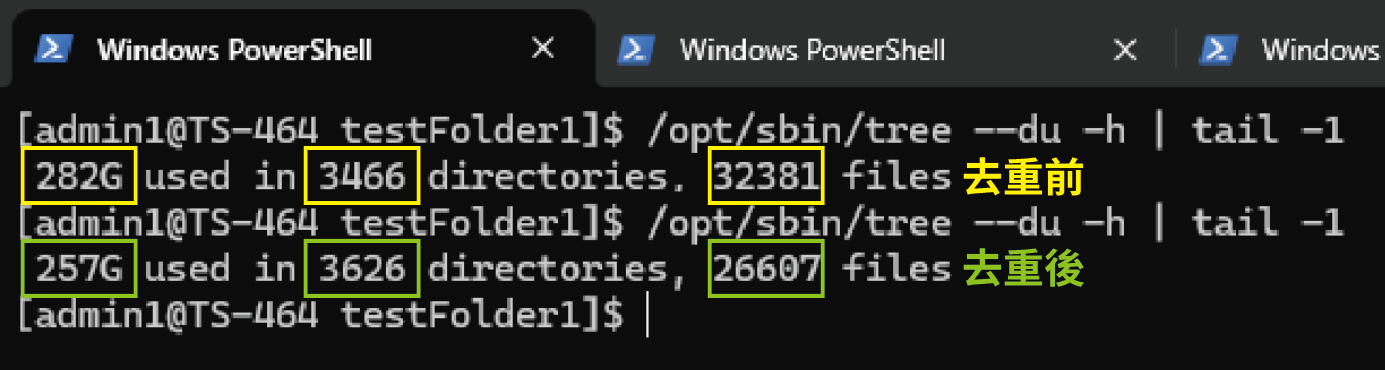
En nuestra prueba para este artículo, el directorio original sumaba 282 GB y contenía 32.381 archivos. Tras la deduplicación, el tamaño total se redujo entre un 8 y un 17 %. El directorio estaba ubicado en un SSD del TS-464, y toda la operación duró aproximadamente 30 segundos. Después de la operación, no solo se ahorró una cantidad considerable de espacio, sino que los tiempos de copia de seguridad también fueron mucho más rápidos.
En este punto, algunos usuarios podrían preguntarse: “¿Qué pasa si quiero conservar los archivos de un directorio específico?” o “Seguro que los archivos de directorios importantes no deberían eliminarse, ¿verdad?”
Por ejemplo, para conservar los archivos en C:\Important, puede usar el siguiente comando:
jdupes -rdN -X “path:Important” .
Los archivos con rutas que contienen “Important” se excluirán de la eliminación.
Limpiar archivos duplicados no solo consiste en liberar unos cuantos gigabytes de espacio de disco; también puede considerarse una forma de ordenar digitalmente. Con herramientas de alto rendimiento como jdupes, la comparación manual que antes llevaba días puede completarse en minutos gracias a la automatización. Esto aumenta significativamente la eficiencia de NAS Almacenamiento, agiliza el proceso de copia de seguridad y garantiza que cada fragmento de datos bajo la estrategia de copia de seguridad 3-2-1-1-0 siga siendo único y valioso.
Al cultivar el hábito de limpiar regularmente y utilizar las herramientas adecuadas, un NAS puede funcionar realmente como un “centro de datos de alto rendimiento”, asegurando que cada bit de Almacenamiento se utilice de forma óptima.