Categories

Blog posts about QNAP's products and technologies.
Egal ob internes Festplattenlaufwerk, externes Laufwerk oder NAS – doppelte Dateien sind mit der Zeit fast unvermeidlich. Das gilt für Einzelanwender und erst recht für Mehrbenutzerumgebungen. Im Laufe der Zeit nehmen diese Duplikate immer weiter zu, verschwenden Speicherplatz, verlangsamen Sicherungen und gefährden möglicherweise Ihr Daten.
Ist es wirklich so schlimm? Sehen wir uns ein paar einfache Beispiele an.
1. Nach einer Fotosession kopiert ein Fotograf die Bilder von der Speicherkarte der Kamera auf das NAS, vergisst aber, die Karte zu formatieren. Beim nächsten Mal, wenn neue Fotos gemacht werden, kopiert er die gesamte Speicherkarte erneut auf das NAS. Unabhängig davon, ob er erkennt, dass es sich um Duplikate handelt, oder sich einfach nicht erinnert, was bereits übertragen wurde, landen doppelte Kopien auf demselben Laufwerk, was bei Backups wenig zur Hilfe beiträgt.
2. Ein Ausstellungskoordinator in der Marketingabteilung speichert ein zentrales Bild für einen Messestand in Ordner A. Ein Designer derselben Abteilung speichert ebenfalls eine Kopie desselben Bildes in Ordner B, um seine Arbeit zu erleichtern. Später, beim Übergeben der Dateien an eine externe Designagentur, wird ein weiterer Ordner erstellt, um dieselbe Datei für die Agentur zugänglich zu machen. Am Ende enthält das Festplattenlaufwerk drei Kopien derselben Datei. Eine Woche später greift die von dem erfahrenen MIS-Team eingerichtete 3-2-1-1-0-Backup-Strategie und sorgt dafür, dass diese Duplikate noch mehrfach gesichert werden.
Beide der oben genannten Szenarien sind sehr häufig. Neben der Verschwendung von Speicherplatz und Zeit kann eine zu große Anzahl doppelter Dateien das Versionsmanagement erschweren. Mit der Zeit wird es schwierig, identische Dateien zu erkennen, was sogar zu versehentlichen Löschungen führen kann – sodass keine gültige Kopie mehr vorhanden ist.
Daher ist es eine gute Gewohnheit, Ihre Dateien regelmäßig zu bereinigen, um sowohl Zeit als auch Speicher zu sparen. Das manuelle Durchgehen jeder einzelnen Datei ist jedoch sehr zeitaufwendig, daher empfiehlt es sich, Drittanbieter-Tools für diese Aufgabe zu nutzen.
Wenn Dinge nicht richtig benannt sind, ergeben Erklärungen keinen Sinn. Bevor wir fortfahren, klären wir die Aufgabe: Wir suchen auf dem NAS nach Dateien und Fotos, die exakte Duplikate sind. Manche Anwendungen konzentrieren sich auf das „Finden ähnlicher Fotos“, aber das ist eine völlig andere Aufgabe, über die wir ein anderes Mal sprechen können.
Was das Erkennen exakt identischer Fotos betrifft, so existieren Fotos auf einem Festplattenlaufwerk als Dateien. Dateien mit identischem Inhalt sind im Grunde dasselbe Bild. Dadurch lässt sich das Kernziel der Aufgabe vereinfachen: Es geht nur darum, doppelte Dateien zu finden. Dieser Vorgang wird allgemein als „Deduplizierung“ bezeichnet.
Hier kommt die Herausforderung: Wie finden und vergleichen Sie diese? Die meisten Tools verwenden denselben grundlegenden Algorithmus und dieselbe Logik, die im Allgemeinen wie folgt funktioniert:
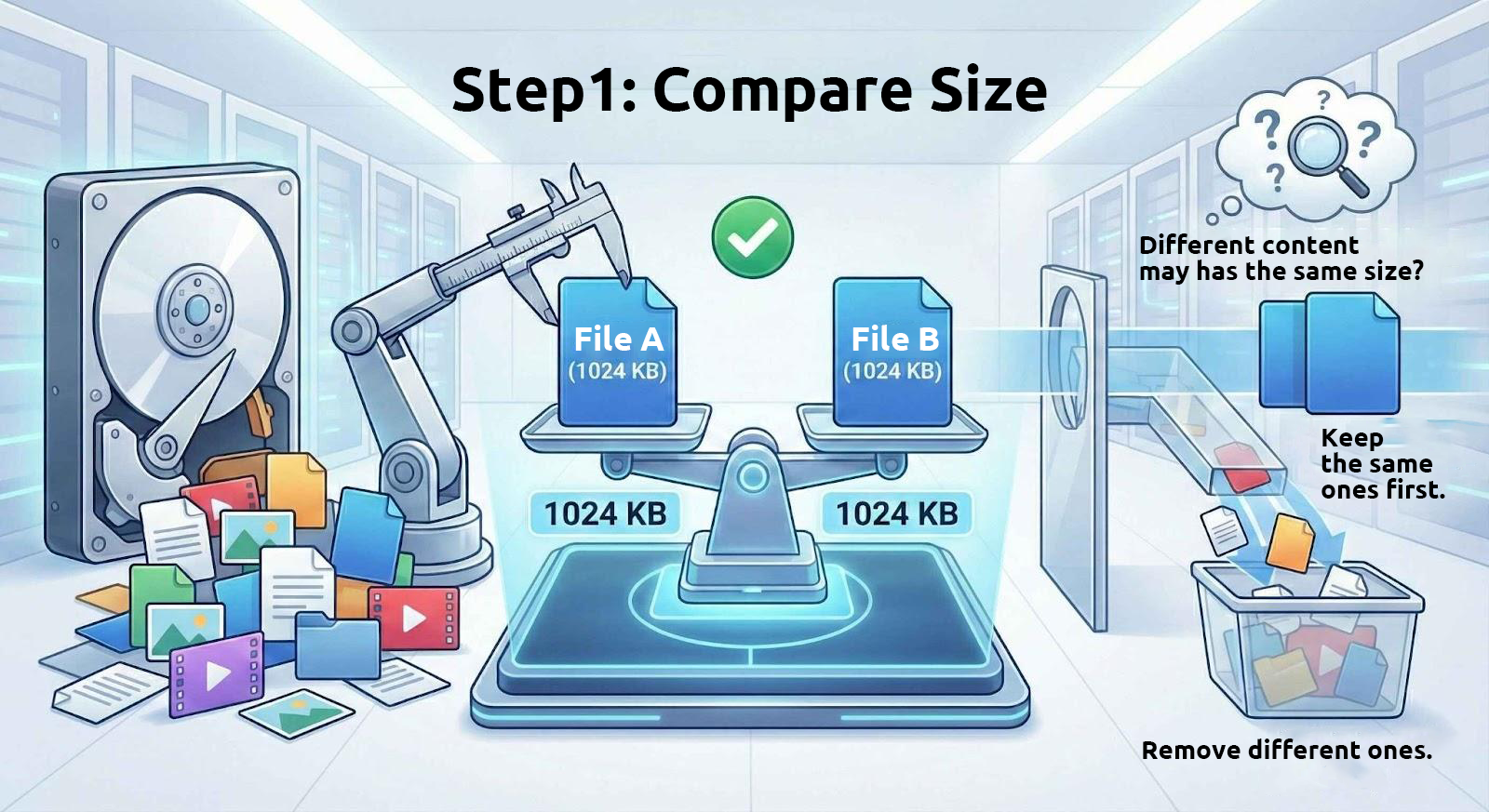
1. Zuerst Dateigrößen vergleichen
Dateien mit identischem Inhalt haben immer die gleiche Größe. Daher filtern diese Tools zunächst Dateien mit identischer Größe aus dem Laufwerk heraus.
Allerdings haben Dateien mit gleicher Größe nicht zwangsläufig identischen Inhalt. Zum Beispiel werden viele geteilte Archivdateien in gleich große Teile aufgeteilt, und Textdateien mit der gleichen Anzahl an Zeichen haben ebenfalls die gleiche Größe. Daher ist die Verwendung der Dateigröße allein zur Bestimmung identischer Dateien nur der erste Schritt.
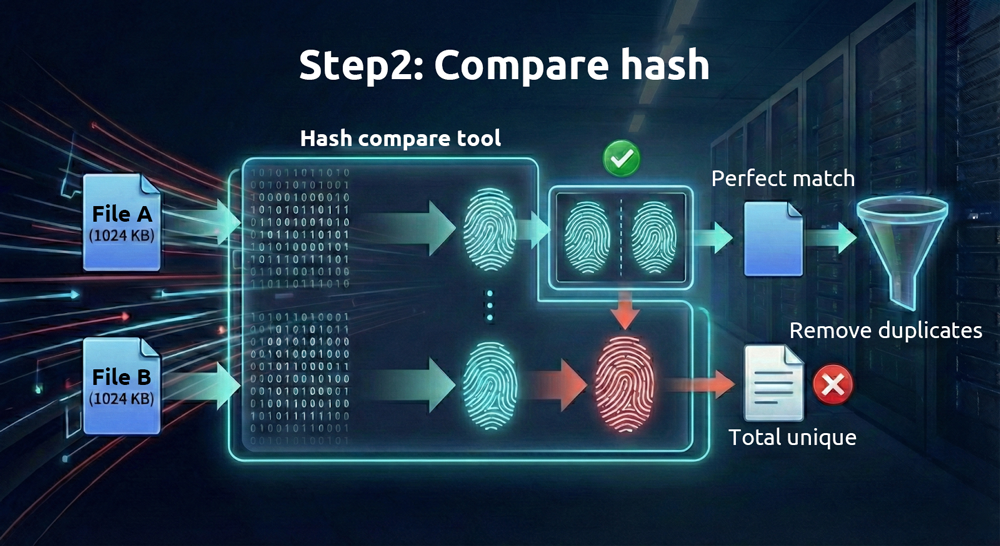
2. Vergleichen Sie dann die „Fingerabdrücke“ der Dateien
Da digitale Dateien in binärer Form gespeichert werden, kann aus dem Inhalt jeder Datei mithilfe mathematischer Algorithmen eine einzigartige hexadezimale Zeichenfolge – der sogenannte „Hashwert“ – erzeugt werden. Verschiedene Algorithmen erzeugen unterschiedliche Hashwerte. Algorithmen, die mehr Rechenleistung erfordern (wie SHA-512), sind zuverlässiger, benötigen aber mehr Zeit, während solche mit geringerem Rechenaufwand (wie MD5) schneller, aber weniger zuverlässig sind.
Solange die Dateien unterschiedlich sind, ist es unter normalen Umständen sehr unwahrscheinlich, dass diese Hashwerte identisch sind. Ein technischer Begriff dafür ist „Kollision“; der einzige Unterschied besteht darin, wie leicht sie gefälscht werden können. Man kann einen Hashwert als einzigartigen Fingerabdruck jeder Datei betrachten. Haben zwei Dateien identische Fingerabdrücke, sind sie identisch.
Angesichts der hohen Zuverlässigkeit von Hash-Vergleichen stellt sich die Frage, warum es dennoch notwendig ist, zunächst die Dateigrößen zu überprüfen? Dies kann Hilfe Zeit und Ressourcen sparen. Der Vergleich von Hashwerten ist rechenintensiv, während das Ermitteln identischer Dateigrößen für moderne Computer nahezu mühelos ist. Indem Sie die Anzahl der Dateien zunächst anhand der Größe eingrenzen, bevor Sie Hash-Vergleiche durchführen, wird der Prozess deutlich effizienter.
Viele Desktop-Anwendungen auf Windows und macOS können diese Aufgabe übernehmen. Befinden sich die Dateien jedoch bereits auf einer NAS, kann das Ausführen des Prozesses direkt auf der NAS selbst erheblich Zeit sparen. Dafür gibt es zwei Hauptgründe:
1. Netzwerkübertragungszeit
Die Berechnung von Hash-Werten erfordert das vollständige Auslesen des Inhalts jeder Datei. Häufiges Lesen von NAS-Dateien von einem lokalen Computer ist ineffizient.
2. Native Tool-Unterstützung
Obwohl NAS-Geräte in der Regel nicht mit einfachen integrierten Deduplizierungswerkzeugen ausgestattet sind (QNAP HBS bietet jedoch Deduplizierung für Sicherungsaufgaben, was in einem späteren Artikel behandelt wird), gibt es eine Vielzahl von Linux-Dienstprogrammen, die diese Aufgabe übernehmen können.
Aktivieren Sie auf einem QNAP NAS zunächst SSH und melden Sie sich remote an der Kommandozeile an. Installieren Sie dann das jdupes-Dienstprogramm über QPKG. Beachten Sie, dass jdupes kein offizielles QNAP-Dienstprogramm ist; falls es Sicherheit-Bedenken gibt, empfiehlt es sich, diese Aufgaben in einer Docker-Umgebung durchzuführen.
Die Befehlszeilenoptionen für jdupes sind recht einfach. Um beispielsweise doppelte Dateien im aktuellen Verzeichnis einschließlich aller Unterverzeichnisse zu finden, verwenden Sie folgenden Befehl:
jdupes -r .
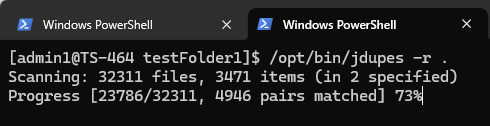
Die Option „-r“ steht für rekursiv und der Punkt „.“ bedeutet, dass die Suche im aktuellen Verzeichnis beginnt. Nach dem Ausführen beginnt das Dienstprogramm mit dem Scannen der Dateiinhalte; die benötigte Zeit hängt von der Anzahl und Größe der Dateien ab. Da dieses Tool häufig vom Laufwerke innerhalb des NAS liest, ist die Ausführung auf einem Solid-State-Laufwerk (SSD) deutlich schneller.
Nach Abschluss des Vergleichs listet das Dienstprogramm alle doppelten Dateien auf und ordnet sie in Gruppen, wie unten gezeigt:
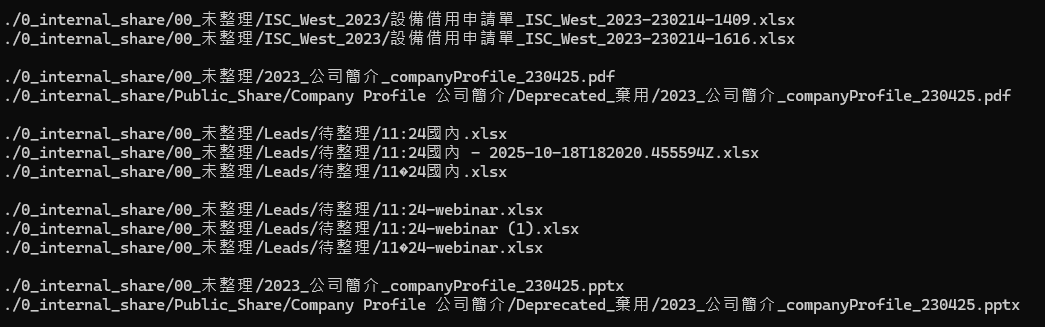
Sie werden feststellen, dass viele Dateien mit unterschiedlichen Namen oder Pfaden im Wesentlichen identisch sind. Nachdem Sie doppelte Dateien identifiziert haben, besteht der nächste Schritt darin, sie zu löschen. Fügen Sie dem vorherigen Befehl ein „d“ hinzu, zum Beispiel:
Jdupes -rd .
Bei der Anzeige der Ergebnisse fordert das Dienstprogramm den Benutzer auf, auszuwählen, welche Datei behalten werden soll; die übrigen werden gelöscht. Diese Methode funktioniert gut bei einer kleinen Anzahl von Dateien, ist jedoch bei einer großen Menge – beispielsweise Tausenden von Duplikatsätzen – unpraktisch, da jede Auswahl einzeln bestätigt werden müsste.
An dieser Stelle können Sie dem Befehl ein „N“ hinzufügen, zum Beispiel:
Jdupes -rdN .
Das „N“ bedeutet: „Nicht nachfragen, sondern einfach die erste gefundene Übereinstimmung behalten“, alle anderen werden automatisch gelöscht. Nach Ausführung dieses Befehls bleibt im Zielverzeichnis nur noch eine Kopie jeder identischen Datei erhalten, wodurch effektiv eine Deduplizierung erfolgt.

In der obigen Abbildung werden Dateien mit dem Präfix „+“ behalten, während Dateien mit dem Präfix „-“ gelöscht werden.
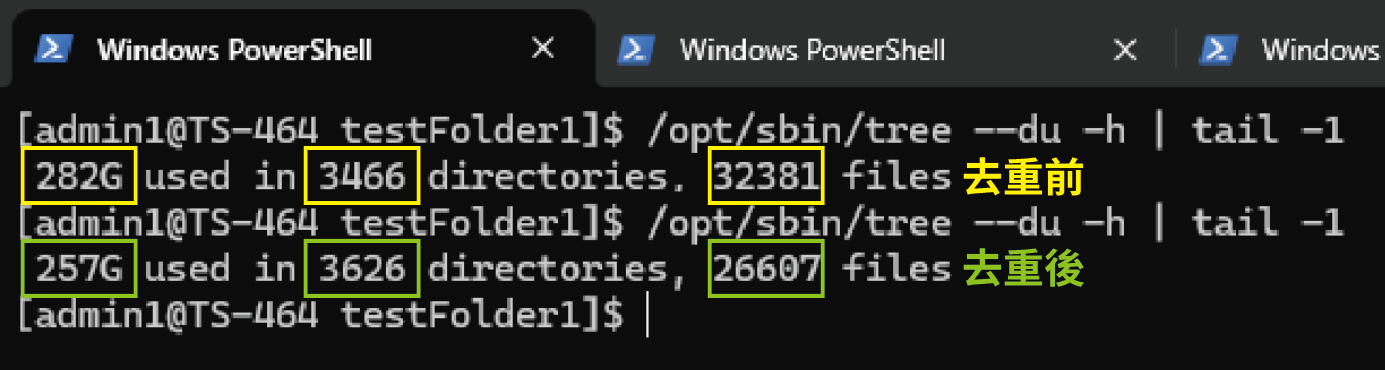
In unserem Test für diesen Artikel umfasste das ursprüngliche Verzeichnis 282 GB und enthielt 32.381 Dateien. Nach der Deduplizierung wurde die Gesamtgröße um 8–17 % reduziert. Das Verzeichnis befand sich auf einem SSD im TS-464 und der gesamte Vorgang dauerte etwa 30 Sekunden. Nach der Ausführung wurde nicht nur erheblich Speicherplatz eingespart, sondern auch die Sicherungszeiten waren deutlich kürzer.
An dieser Stelle fragen sich manche Nutzer vielleicht: „Was ist, wenn ich Dateien in einem bestimmten Verzeichnis behalten möchte?“ oder „Dateien in wichtigen Verzeichnissen sollten doch sicher nicht gelöscht werden, oder?“
Um beispielsweise die Dateien in C:\Important zu behalten, können Sie den folgenden Befehl verwenden:
jdupes -rdN -X „path:Important“ .
Dateien mit Pfaden, die „Important“ enthalten, werden vom Löschen ausgeschlossen.
Das Bereinigen doppelter Dateien dient nicht nur dazu, ein paar Gigabyte Platte-Speicherplatz freizugeben; es kann als digitale Entrümpelung betrachtet werden. Mit leistungsstarken Tools wie jdupes kann der manuelle Vergleich, der früher Tage dauerte, durch Automatisierung in wenigen Minuten erledigt werden. Das steigert die Effizienz von NAS Speicher erheblich, vereinfacht den Sicherungsprozess und stellt sicher, dass jedes einzelne Daten nach der 3-2-1-1-0-Backup-Strategie einzigartig und wertvoll bleibt.
Wenn Sie sich eine regelmäßige Bereinigungsroutine angewöhnen und die richtigen Tools einsetzen, kann ein NAS tatsächlich als „High-Performance-Daten-Zentrum“ fungieren und sicherstellen, dass jeder Teil von Speicher optimal genutzt wird.