Categories

Blog posts about QNAP's products and technologies.
Qu’il s’agisse d’un disque dur interne, d’un lecteur externe ou d’un NAS, les fichiers en double sont presque inévitables avec le temps. Cela concerne les utilisateurs individuels—et encore plus dans les environnements multi-utilisateurs. Au fil du temps, ces fichiers en double continuent de s’accumuler, gaspillant le Espace de stockage, ralentissant les sauvegardes et risquant potentiellement de mettre votre données en danger.
Est-ce vraiment si grave ? Jetons un œil à quelques exemples simples.
1. Après une séance photo, un photographe copie les photos de la carte mémoire de l’appareil vers le NAS mais oublie de formater la carte. Lors de la prochaine séance, il copie à nouveau toute la carte mémoire sur le NAS. Qu’il se rende compte ou non que les fichiers sont en double, ou qu’il ne se souvienne plus de ce qui a déjà été transféré, des copies en double se retrouvent sur le même lecteur, ce qui n’aide pas vraiment à Aide lors des sauvegardes.
2. Un coordinateur d’exposition du service marketing enregistre une image clé pour un stand dans le dossier A. Un designer du même service enregistre également une copie de la même image dans le dossier B pour faciliter son travail. Plus tard, lors de la transmission des fichiers à une agence de design externe, ils créent encore un autre dossier pour stocker le même fichier afin que l’agence puisse y accéder. Au final, le disque dur se retrouve avec trois copies du même fichier. Une semaine plus tard, la stratégie de sauvegarde 3-2-1-1-0, mise en place par l’équipe MIS expérimentée, s’active, entraînant la sauvegarde de ces fichiers en double plusieurs fois de plus.
Les deux scénarios ci-dessus sont très courants. En plus de gaspiller du Espace de stockage et du temps, avoir trop de fichiers en double peut rendre la gestion des versions difficile. Avec le temps, il peut devenir difficile de savoir quels fichiers sont identiques, ce qui peut même entraîner une suppression accidentelle—laissant aucune copie valide derrière.
Par conséquent, nettoyer régulièrement vos fichiers est une bonne habitude pour gagner du temps et du Stockage. Cependant, passer en revue les fichiers un par un peut être très chronophage, il est donc préférable d’utiliser des outils tiers pour accomplir cette tâche.
Si les choses ne sont pas correctement nommées, les explications n’auront pas de sens. Avant de continuer, clarifions la tâche : nous recherchons sur le NAS les fichiers et photos qui sont des doublons exacts. Certaines applications se concentrent sur la « recherche de photos similaires », mais il s’agit d’une tâche complètement différente, dont nous pourrons parler une autre fois.
Pour identifier des photos strictement identiques, puisque les photos existent sur un disque dur sous forme de fichiers, tous les fichiers ayant un contenu identique sont essentiellement la même image. Cela nous permet de simplifier l’objectif principal de la tâche : il suffit de trouver les fichiers en double. Ce processus est couramment appelé « déduplication ».
Voici le défi : comment les trouver et les comparer ? La plupart des outils suivent le même algorithme et la même logique de base, qui fonctionnent généralement comme suit :
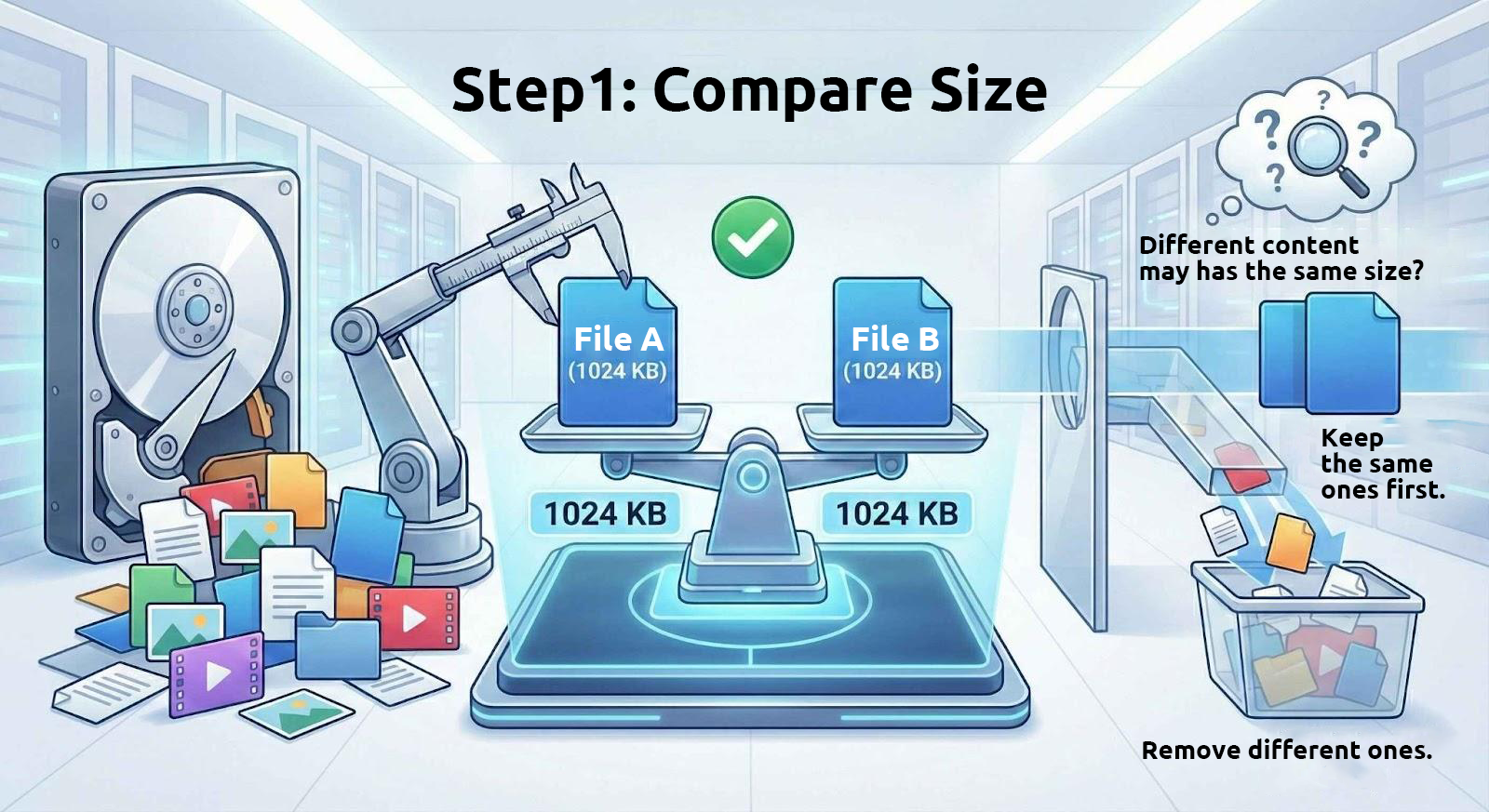
1. Comparer d’abord la taille des fichiers
Les fichiers ayant un contenu identique ont toujours la même taille. Par conséquent, ces outils commencent par filtrer les fichiers de taille identique depuis le lecteur.
Cependant, des fichiers de même taille n’ont pas forcément un contenu identique. Par exemple, de nombreux fichiers d’archives découpés sont divisés en parties de taille fixe, et des fichiers texte ayant le même nombre de caractères auront aussi la même taille. Ainsi, utiliser uniquement la taille du fichier pour déterminer si des fichiers sont identiques n’est qu’une première étape.
2. Comparez ensuite les « empreintes digitales » des fichiers
Comme les fichiers numériques sont stockés sous forme binaire, une chaîne hexadécimale unique—appelée « valeur de hachage »—peut être générée à partir du contenu de chaque fichier à l’aide d’algorithmes mathématiques. Différents algorithmes produisent différentes valeurs de hachage. Les algorithmes nécessitant plus de calculs (comme SHA-512) sont plus fiables mais plus lents, tandis que ceux nécessitant moins de calculs (comme MD5) sont plus rapides mais moins fiables.
Tant que les fichiers sont différents, ces valeurs de hachage ont, dans des circonstances normales, très peu de chances d’être identiques. Le terme technique pour cela est « collision » ; la seule différence réside dans la facilité avec laquelle elles peuvent être falsifiées. On peut considérer une valeur de hachage comme une empreinte digitale unique pour chaque fichier. Si deux fichiers ont des empreintes identiques, ils sont identiques.
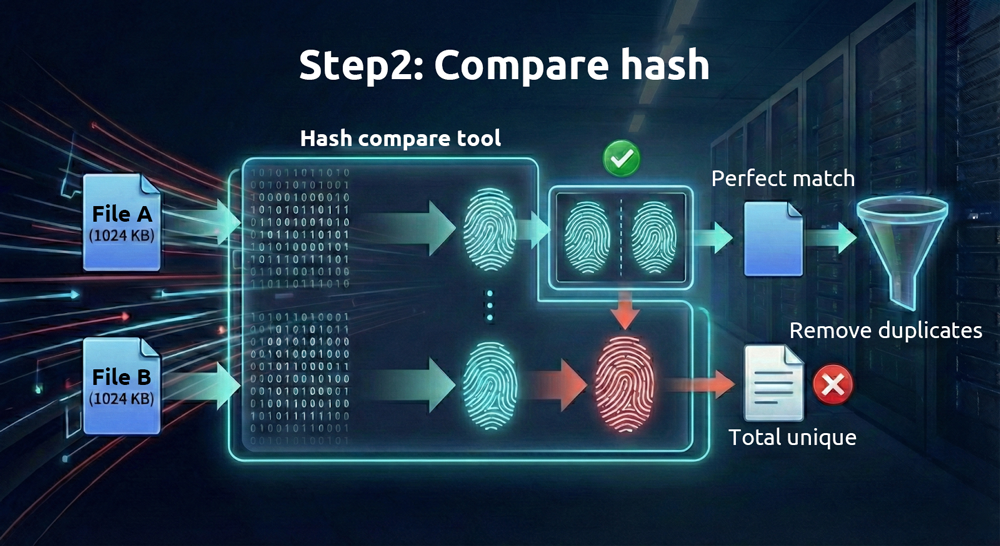
Étant donné la grande fiabilité des comparaisons de hachage, pourquoi est-il encore nécessaire de vérifier d’abord la taille des fichiers ? Cela Aide permet d’économiser du temps et des ressources. Comparer les valeurs de hachage est coûteux en calcul, mais identifier les fichiers de taille identique est presque instantané pour les ordinateurs modernes. En réduisant d’abord le nombre de fichiers selon leur taille avant de comparer les hachages, le processus devient beaucoup plus efficace.
De nombreuses applications de bureau sur Windows et macOS peuvent effectuer cette tâche. Cependant, si les fichiers sont déjà sur un NAS, exécuter le processus directement sur le NAS lui-même peut faire gagner beaucoup de temps. Il y a deux raisons principales à cela :
1. Temps de transfert réseau
Le calcul des valeurs de hachage nécessite la lecture de l’intégralité du contenu de chaque fichier. Effectuer des lectures fréquentes de fichiers NAS depuis un ordinateur local est inefficace.
2. Prise en charge native des outils
Bien que les appareils NAS ne soient généralement pas équipés d’outils de déduplication intégrés simples (QNAP HBS propose la déduplication pour les tâches de sauvegarde, qui sera abordée dans un prochain article), il existe un large éventail d’utilitaires Linux capables d’accomplir cette tâche.
Sur un QNAP NAS, commencez par activer SSH et connectez-vous à la ligne de commande à distance. Ensuite, installez l’utilitaire jdupes via QPKG. Notez que jdupes n’est pas un utilitaire officiel de QNAP ; s’il y a des préoccupations liées à Sécurité, il est conseillé d’effectuer ces tâches dans un environnement Docker.
Les options en ligne de commande pour jdupes sont assez simples. Par exemple, pour localiser les fichiers en double dans le dossier courant, y compris tous les sous-dossiers, utilisez la commande suivante :
jdupes -r .
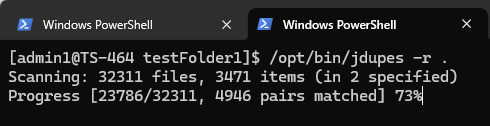
L’option « -r » signifie récursif, et le « . » indique que la recherche commence dans le dossier courant. Une fois exécuté, l’utilitaire commence à analyser le contenu des fichiers, et le temps requis dépend du nombre et de la taille des fichiers. Comme cet outil lit fréquemment depuis le lecteurs à l’intérieur du NAS, l’exécuter sur un lecteur à semi-conducteurs (SSD) sera beaucoup plus rapide.
Une fois la comparaison terminée, l’utilitaire liste tous les fichiers en double et les organise en groupes, comme illustré ci-dessous :
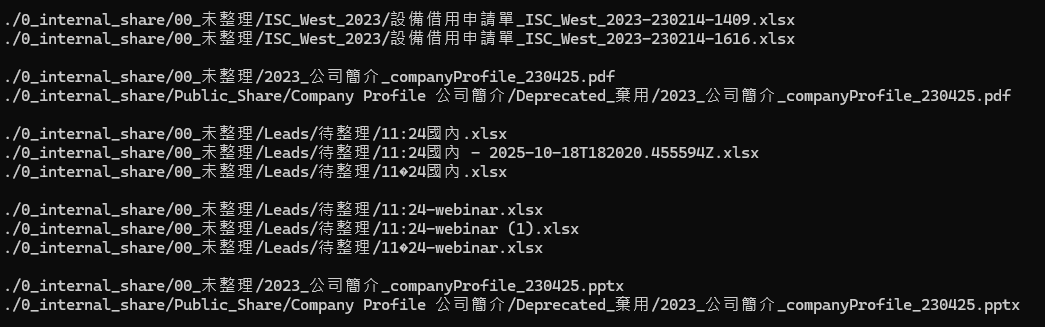
Vous remarquerez que de nombreux fichiers portant des noms ou des chemins différents sont en réalité identiques. Après avoir identifié les fichiers en double, l’étape suivante consiste à les supprimer. Ajoutez « d » à la commande précédente, par exemple :
Jdupes -rd .
Lors de l’affichage des résultats, l’utilitaire invite l’utilisateur à sélectionner le fichier à conserver ; les autres sont supprimés. Cette méthode fonctionne bien pour un petit nombre de fichiers, mais lorsqu’il s’agit de grandes quantités — par exemple, des milliers de groupes de doublons — il n’est pas pratique de confirmer chaque cas individuellement.
À ce stade, vous pouvez ajouter « N » à la commande, comme ceci :
Jdupes -rdN .
Le « N » signifie « Ne pas demander, garder simplement le premier fichier correspondant trouvé », et tous les autres seront supprimés automatiquement. Après l’exécution de cette commande, une seule copie de chaque fichier identique restera dans le répertoire cible, ce qui permet de le dédupliquer efficacement.

Dans l’illustration ci-dessus, les fichiers préfixés par « + » sont conservés, tandis que ceux préfixés par « – » sont supprimés.
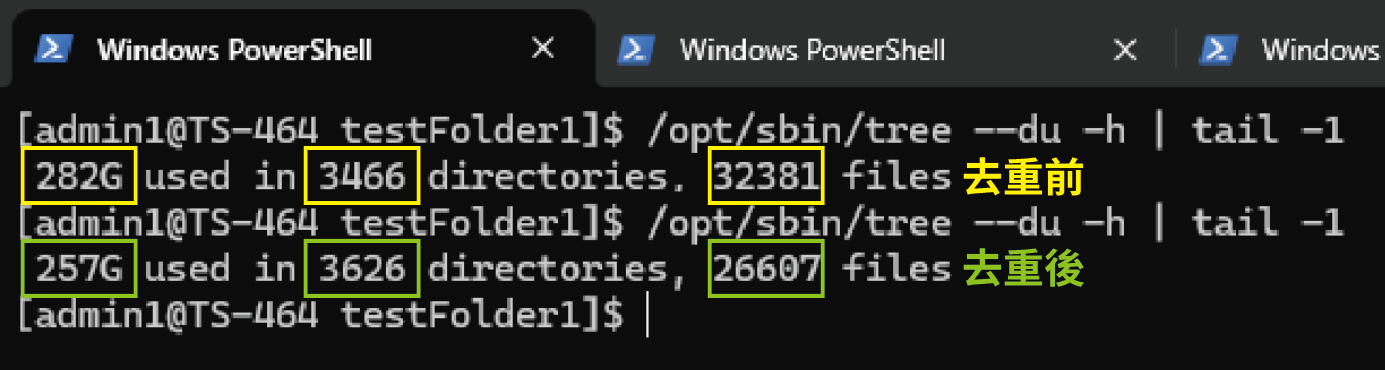
Dans notre test pour cet article, le répertoire d’origine totalisait 282 Go et contenait 32 381 fichiers. Après la déduplication, la taille totale a été réduite de 8 à 17 %. Le répertoire était situé sur un SSD dans le TS-464, et l’ensemble de l’opération a pris environ 30 secondes. Après l’opération, non seulement une quantité considérable d’espace a été économisée, mais les temps de sauvegarde ont également été beaucoup plus rapides.
À ce stade, certains utilisateurs pourraient se demander : « Que faire si je veux conserver les fichiers dans un répertoire spécifique ? » ou « Les fichiers dans les répertoires importants ne devraient sûrement pas être supprimés, n’est-ce pas ? »
Par exemple, pour conserver les fichiers dans C:\Important, vous pouvez utiliser la commande suivante :
jdupes -rdN -X « path:Important » .
Les fichiers dont le chemin contient « Important » seront exclus de la suppression.
Nettoyer les fichiers en double ne consiste pas seulement à libérer quelques gigaoctets d’espace disque ; cela peut être considéré comme une forme de désencombrement numérique. Avec des outils haute performance comme jdupes, la comparaison manuelle qui prenait autrefois des jours peut être réalisée en quelques minutes grâce à l’automatisation. Cela améliore considérablement l’efficacité NAS Stockage, rationalise le processus de sauvegarde et garantit que chaque élément de données dans la stratégie de sauvegarde 3-2-1-1-0 reste unique et précieux.
En adoptant une habitude de nettoyage régulier et en utilisant les bons outils, un NAS peut réellement fonctionner comme un « centre données haute performance », garantissant que chaque bit de Stockage est utilisé de manière optimale.